11.1 Propiedades de un estimador.
Cualquier estimador que se precie de ser un buen estimador debe cumplir con 3 propiedades deseables para hacer inferencia.
- El estimador debe ser insesgado: un estimador se dice es insesgado cuando la esperanza de su estadístico es igual al valor del parámetro siendo estimado. Se escribe el sesgo \(B(\hat{\theta})\) como: \[B(\hat{\theta}) = E[\hat{\theta}] - \theta\]
Por ejemplo, podemos calcular la esperanza del estadístico \(\bar{X}\) como \(E[\bar{X}] = E\left[\frac{1}{n}\sum_{i=1}^n X_i\right]\). Usando las propiedades \(E[cX] = cE[X]\) y \(E[\sum_i X] = \sum_iE[X]\), donde \(c\) es una constante, se tiene que: \[E\left[\frac{1}{n}\sum_{i=1}^n X_i\right] = \frac{1}{n}\sum_{i=1}^n E[X_i]\] Pero como \(E[X] = \mu\) (el valor esperado de una v. a. es su media) entonces: \[\frac{1}{n}\sum_{i=1}^n E[X_i] = \frac{1}{n}\sum_{i=1}^n\mu_X = \mu\] y vemos que el estadístico \(\bar{X}\), que estima \(\mu\) tiene sesgo nulo. Por lo tanto, \(\bar{X}\) es un buen estimador de la media.
- El estimador debe ser eficiente: un estimador \(g(x)\) se dice que es eficiente si de todos los posibles estimadores, \(g(x)\) tiene la mínima varianza posible. Más formalmente, si \(\hat{X_1}\) y \(\hat{X_2}\) son ambos estimadores insesgados de \(X\), entonces se dice que \(\hat{X_1}\) es un estimador más eficiente de \(X\) que \(\hat{X_2}\), si \(\sigma^2_{\hat{X_1}} < \sigma^2_{\hat{X_2}}\).
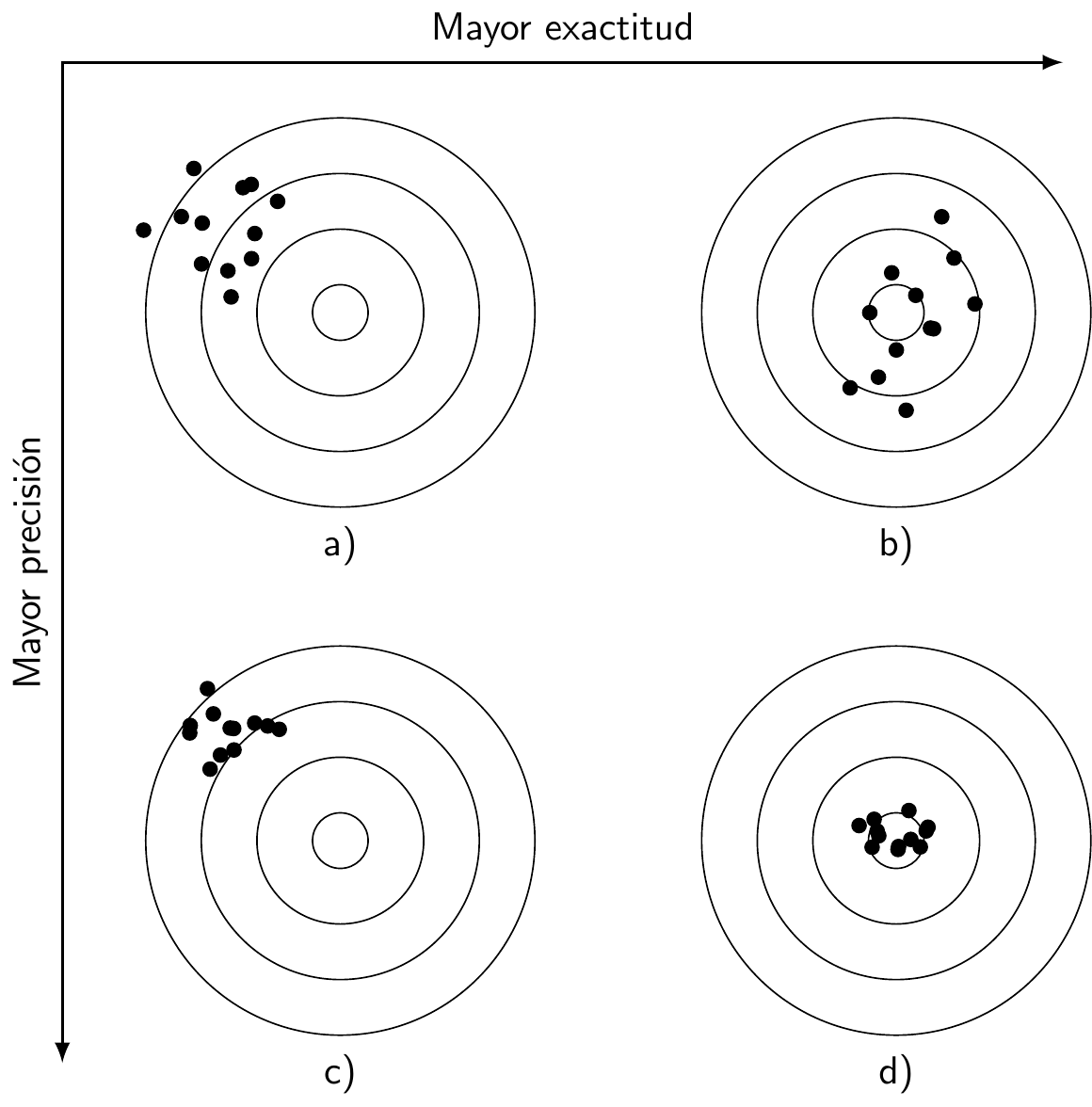
Figure 11.1: Ejemplo gráfico de estimadores: a) sesgado y no eficiente; b) insesgado pero no eficiente; c) sesgado y eficiente; d) insesgado y eficiente.
- El estimador debe ser consistente: se dice que un estimador \(g(x)\) es consistente si este se aproxima a al parámetro \(\theta\) cuando el esfuerzo de muestreo se hace mayor. Formalmente: sea \(X_1, X_2, \ldots, X_n\) variables aleatorias iid que se usan para obtener un estimador \(\hat{\theta}\) de \(\theta\). Se dice que \(\hat{\theta}\) es un estimador consistente si converge en probabilidad a \(\theta\), esto es: \[\lim\limits_{n \to \infty} P\left[\vert\hat{\theta} - \theta\vert\ge\varepsilon\right] = 0\]
El último límite se puede modificar para comprender mejor la propiedad de consistencia. Para ello, se puede usar la desigualdad de Chebyshev \[P\left[\vert\hat{\theta} - \theta\vert\ge\varepsilon\right] \le \frac{\sigma^2_\theta}{\varepsilon^2}, \varepsilon > 0\] y luego, tomando límites a ambos lados, podemos escribir la propiedad de consistencia como: \[\lim\limits_{n \to \infty} \sigma^2_\hat{\theta} = 0\] Entonces, un estimador es consistente, cuando la varianza de este cae cero cuando aumentamos el esfuerzo de muestreo. Dicho de otra forma, el estimador es consistente cuando se acerca más al verdadero valor del parámetro cuando \(n\rightarrow\infty\).
Ahora podemos proceder a estudiar los estimadores puntuales y por intervalos.