8.2 Distribución Ji-Cuadrada.
Se dice que una variable aleatoria continúa \(X\) sigue una distribución Ji-Cuadrada con \(n\) grados de libertad (\(n>0\)), si su función de densidad viene dada por:
\[f(x) = \begin{cases} \frac{1}{\gamma(n/2)}\left(\frac{1}{2}\right)^{n/2}x^{n/2 - 1}e^{-x/2} &\text{ si }x > 0 \\ 0 &\text{ en otro caso}\end{cases}\]
Esta función se distribuye en el intervalo \((0, \infty)\) y su único parámetro son los grados de libertad \(n\) que puede ser cualquier valor positivo, aunque la mayoría de las veces tomará solo valores enteros positivos. En la figura 8.4 se muestra esta distribución para \(n = 1, 2, 5\), y \(8\): a partir de \(n=3\) aparece un pico en la función, el cual se desplaza a valores mayores a medida que \(n\) aumenta.
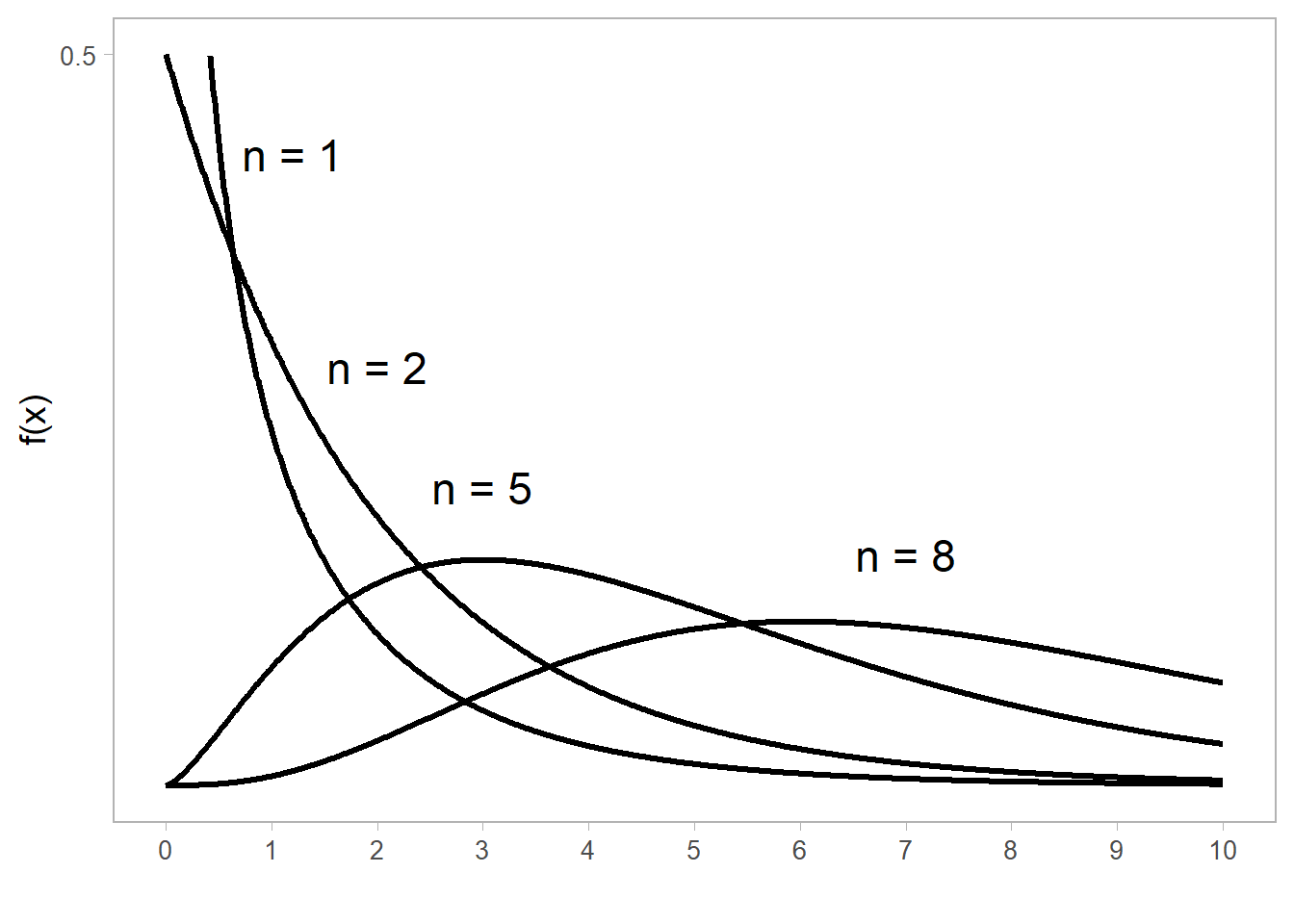
Figure 8.4: Función de densidad de una variable aleatoria Ji-Cuadrada \(\chi^2(n)\).
Si \(X\) sigue una distribución Ji-Cuadrada, escribiremos
\[X \sim \chi^2(n)\]
Su función de distribución viene dada por:
\[F(x) = \int_0^{x} \frac{1}{\gamma(n/2)} \left(\frac{1}{2}\right)^{n/2}u^{n/2 - 1}e^{-u/2}du\]
cuyo gráfico se muestra a comtinuación para una v. a. \(X \sim \chi^2(n = 8)\):
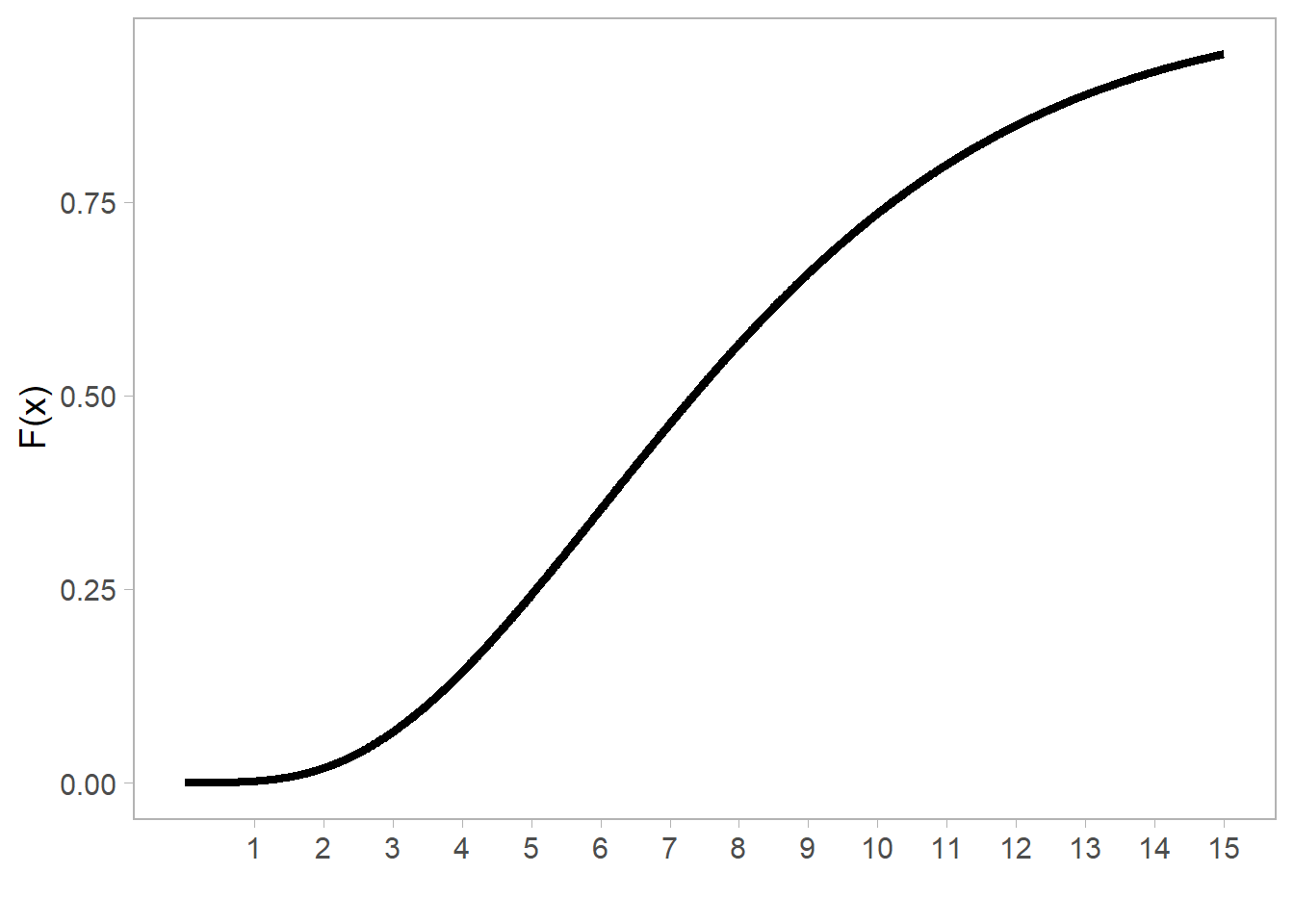
Figure 8.5: Función de distribución acumulada de una variable aleatoria \(\chi^2(n = 8)\).
Es posible obtener valores de probabilidad acumulada en R usando el comando pchisq, el cual da \(F(x) = P(X \le x)\). Para esta distribución, es posible demostrar que:
Antes de ver un ejemplo de calculo de porbabilidades a partir de la función de distribución, es bueno conocer los siguientes resultados.
La distribución Ji-cuadrada se puede obtener como resultado de elevar al cuadrado una variable normal estándar. Si \(X \sim N (0, 1)\), entonces:
\[X^2 \sim \chi^2(1)\]
Este resultado, junto con la siguiente proposición, nos permitirán entender la distribución de v. a. con distribución Ji-Cuadrada.
Sea \(X\) y \(Y\) dos v. a. independientes con distribución \(\chi^2(n)\) y \(\chi^2(m)\), respectivamente. Entonces: \[X + Y \sim \chi^2(n + m)\]
Este resultado se puede extender a la suma de \(n\) variables aleatorias independientes distribuidas como Ji-cuadrado. Esto nos dice que podemos entender cualquier variable aleatoria que sigue una distribución Ji-Cuadrado como una suma de v. a. con la misma distribución pero cada una con un solo grado de libertad, cada una de las cuales se entiende como una v. a. normal estándar al cuadrado.
Se nos permite obtener el siguiente resultado que utilizaremos más adelante cuando hablemos de inferencia estadística, y que es tan importante para realizar inferencia sobre la varianza.
Sean \(X_1, \ldots, X_n\) variables aleatorias independientes, cada una de ellas con distribución \(N(\mu, \sigma^2)\). Entonces: \[\frac{(n - 1)S^2}{\sigma^2} \sim \chi^2(n - 1)\] donde \(S^2 = \frac{1}{n - 1}\sum_{i=1}^n(X_i - \bar{X})^2\) y \(\bar{X} = \frac{1}{n}\sum_{i=1}^nX_i\).
Veamos un ejemplo.
Por ejemplo, se sabe que en madres que no consumieron cocaína al nacer, el peso de los bebés nacidos tiene una desviación entándar de \(\sigma = 696\) g. En un estudio de los efectos que tiene el consumo de cocaína sobre los bebés durante el embarazo, se recolectaron datos de \(n = 190\) madres consumidoras de cocaína.
Por la proposión anterior, sabemos que la variabilidad en el peso de los bebés con respecto al valor conocido se distribuye como una \(\chi^2(n - 1)\). Podemos calcular la probabilidad de que la variabilidad sea la mitad del valor conocido de \(696\) g, calculando la variable aleatoria \((190 - 1) \frac{(1/2)\sigma^2}{\sigma^2} = 189/2 = 94{,}5\), cuya probabilidad se puede calcular en R comopchisq(94.5, 189)que arroja un valor de 0 (se muestra en la gráfica de la izquierda de la figura 8.6). Si la variabilidad es aproximadamente 8% menor al valor conocido, entonces \((190 - 1) \frac{0{,}92\sigma^2}{\sigma^2} = 173{,}88\), entonces se calculapchisq(173.8, 189)que arroja 0.2222 (que se muestra en la gráfica de la derecha de la figura 8.6)
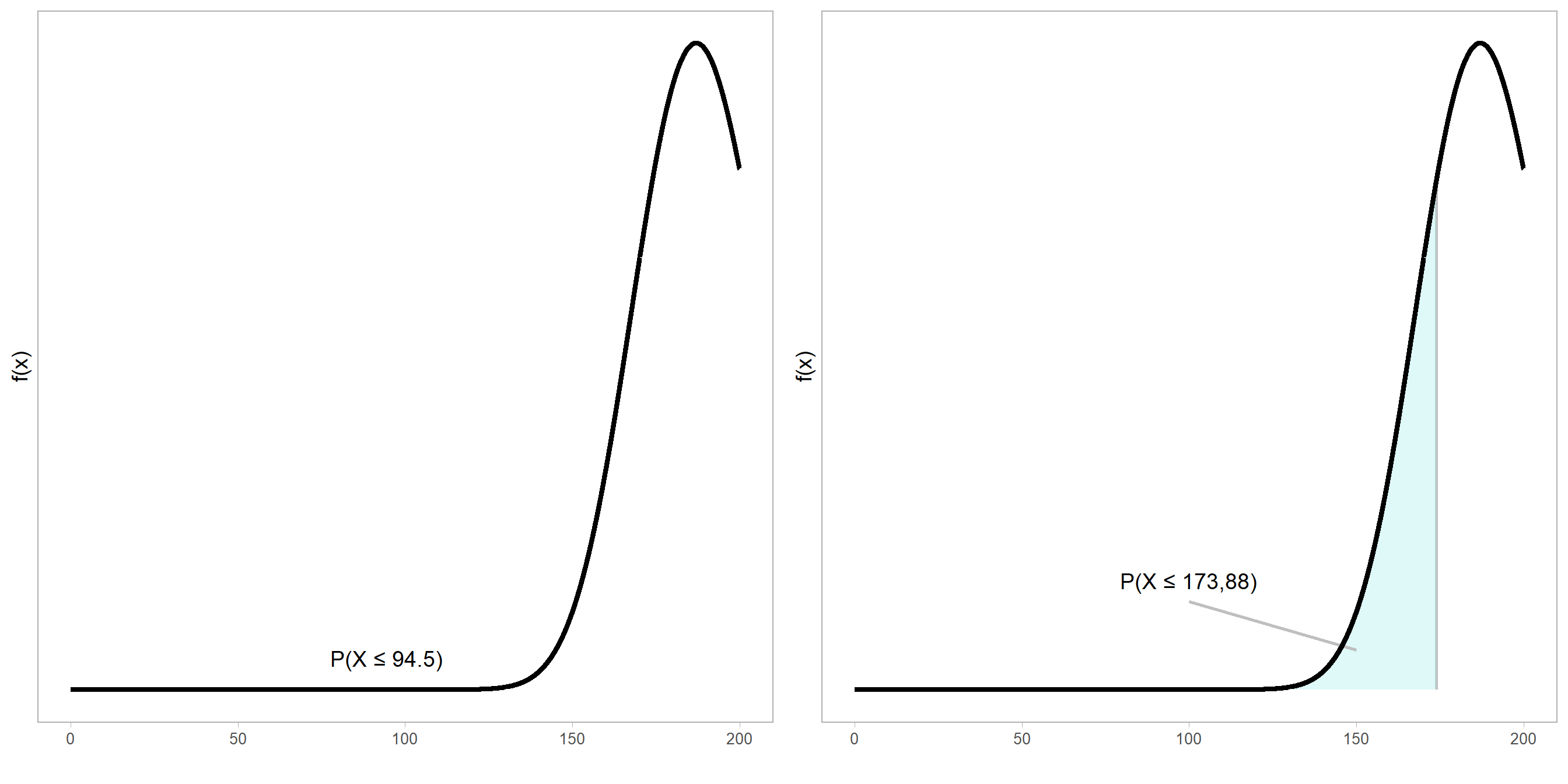
Figure 8.6: Función de densidad de una variable aleatoria \(\chi^2(n = 189)\), donde se muestra de forma grafica la probabilidad acumulada \(P(X \le 94{,}5)\) (a la izquierda) y \(P(X \le 173{,}88)\) (a la derecha).