8.1 Distribución Normal.
La distribución normal (o gaussiana) es de las distribuciones más importantes que estudiaremos. Esta la usaremos con frecuencia más adelante cuando realicemos inferencias a partir de observaciones realizadas en un experimento. Aparecerá primero en el teorema del límite central (capítulo Teoría de Muestreo.), que es uno de los teoremas más importantes que tiene aplicaciones directas en la práctica.
Decimos que una variable aleatoria \(X\) tiene una distribución normal si su función de densidad viene dada por:
\[f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x - \mu)^2}{2\sigma^2}}, \quad -\infty < x < \infty,\]
donde \(\mu, \sigma^2 \in \mathbb{R}\), con \(\sigma^2 > 0\), son los parámetros de la distribución. Si la variable \(X\) se distribuye como normal se escribe:
\[X \sim N(\mu, \sigma^2)\]
La grafica de la función de densidad normal tiene forma de campana, siendo simétrica con respecto a la vertical que pasa por la media \(\mu\), la cual es el centro de la campana. Siendo \(\sigma\) (raíz cuadrada de la varianza \(\sigma^2\)) es la distancia del centro a cualquiera de los puntos de inflexión de la curva (como se muestra en la figura 8.1).
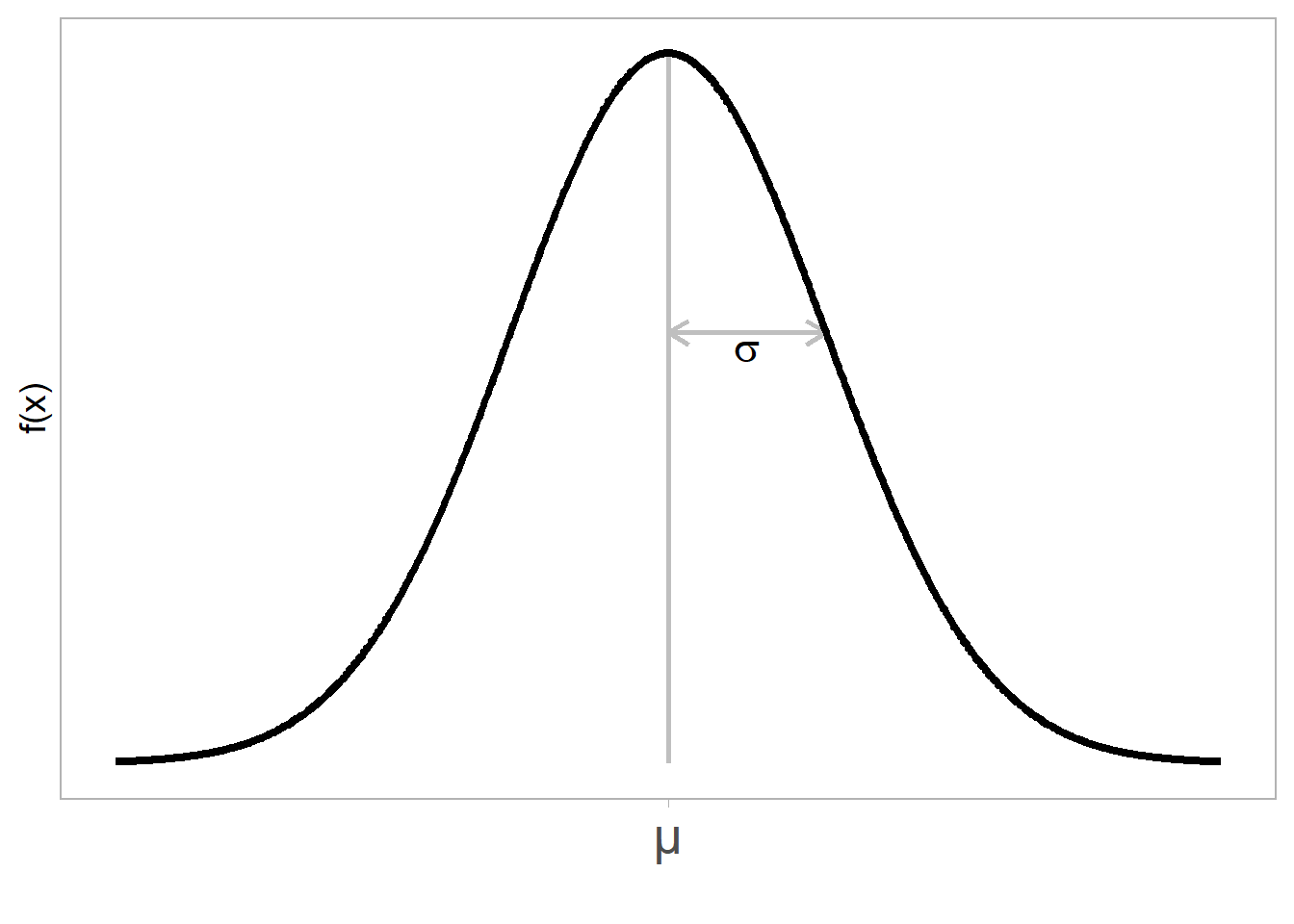
Figure 8.1: Función de densidad de una variable aleatoria normal N(\(\mu, \sigma^2\)).
Esta información se resume como:
\[\begin{aligned} & E(X) = \mu \\ & Var(X) = \sigma^2 \end{aligned}\]La función de distribución viene dada por la integral:
\[F(x) = \int_{-\infty}^x \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(y - \mu)^2}{2\sigma^2}}dy\]
la cual no tiene primitiva analítica asociada y debe resolverse por métodos numéricos. Es posible obtener valores de probabilidad acumulada en R usando el comando pnorm, el cual da \(F(x) = P(X \le x)\), como se muestra en la figura siguiente.
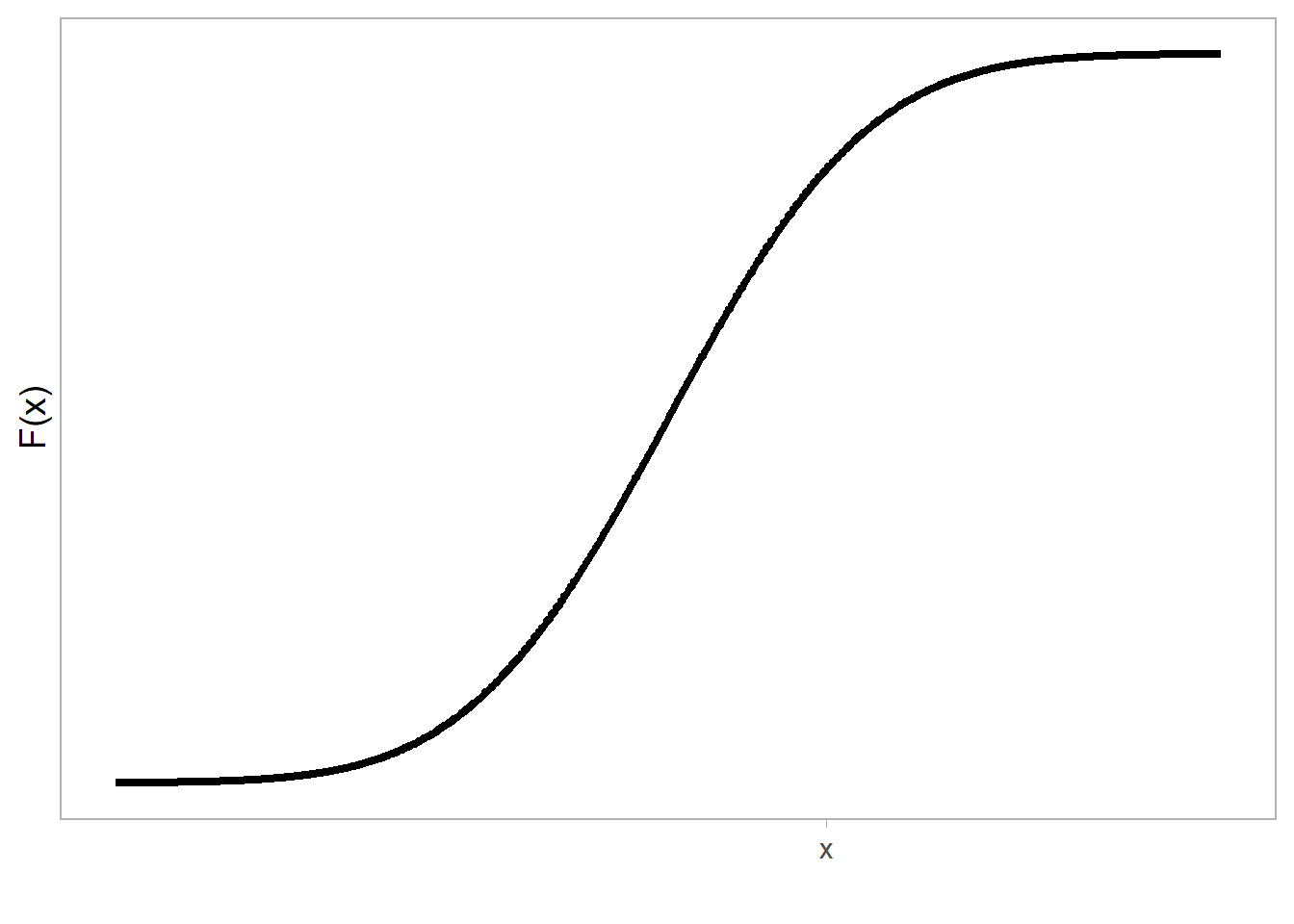
Figure 8.2: Función de distribución acumulada de una variable aleatoria normal N(\(\mu, \sigma^2\)).
Por ejemplo, supongamos que se tiene la variable aleatoria \(X\) que representa la longitud del ala de abejas de cierta granja de apicultores. Se sabe, de estudios anteriores, que la longitud media es de \(1{,}5 \pm 0{,}73\) cm. Los mismos estudios preliminares han mostrado que \(X\) sigue una distribución normal, por lo que se escribe: \[X \sim N(\mu = 1{,}5, \sigma^2 = 0.533)\] Podemos obtener la probabilidad de que una abeja tenga una longitud del ala menor a \(1\) cm, \(P(X \le 1\text{ cm})\) como
pnorm(1, 1.5, 0.73)(figura 8.3, a la izquierda). Si queremos la probabilidad de aquellas con una longitud del ala mayor a \(3\) cm, \(P(X \ge 3\text{ cm}) = 1 - P(X \le 3\text{ cm})\), que se calcula en R como1 - pnorm(3, 1.5, 0.73)(figura 8.3, a la derecha).
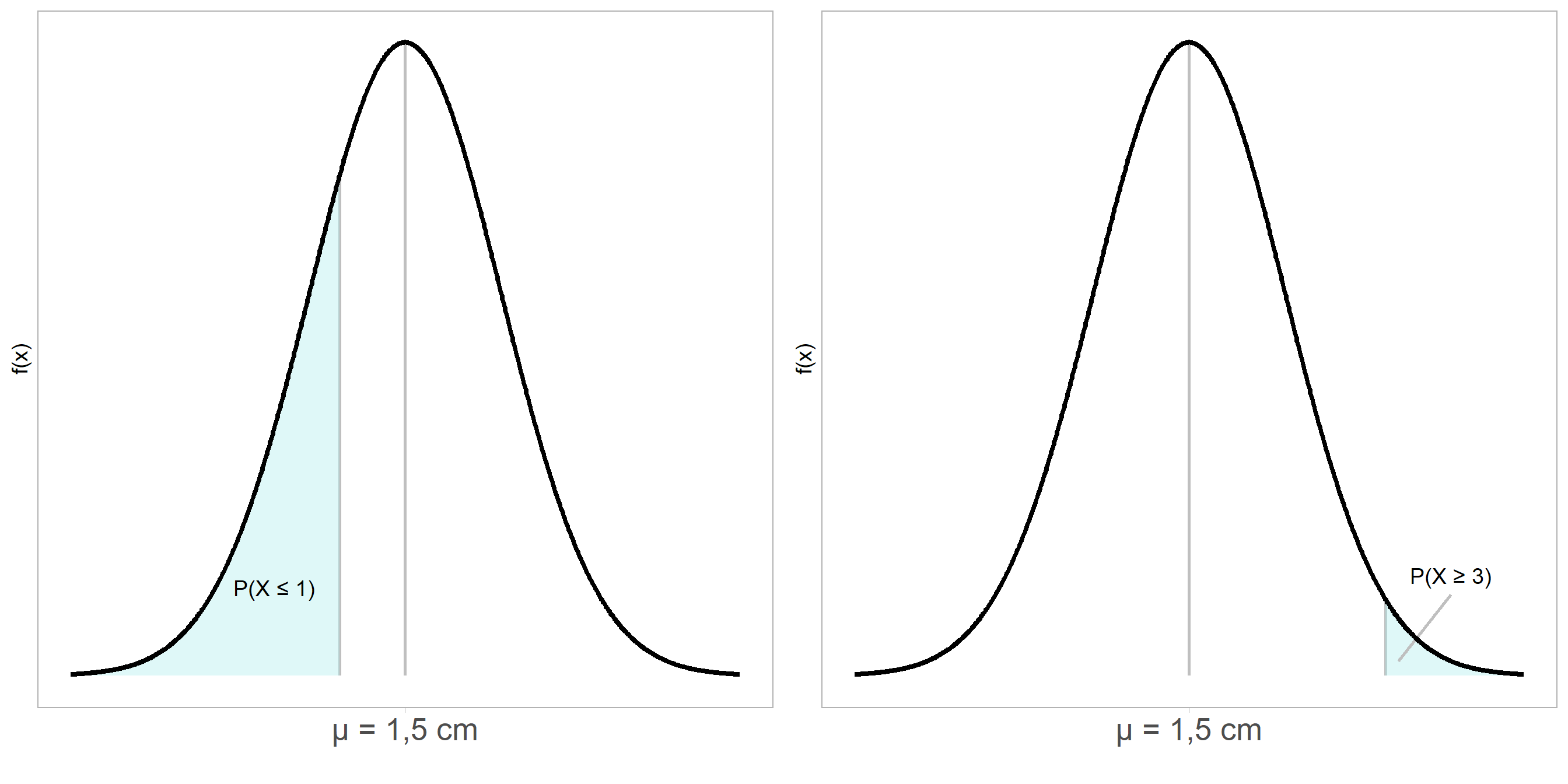
Figure 8.3: Función de densidad de una variable aleatoria normal N(\(\mu = 1{,}5, \sigma^2 = 0{,}532\)), donde se muestra de forma grafica la probabilidad acumulada \(P(X \le 1)\) (a la izquierda) y \(P(X \ge 3)\) (a la derecha).
Notamos, de las figuras del ejemplo, que la probabilidad acumulada se puede entender como el área debajo de la función de densidad para un valor de \(X\) observado o menor, y que para encontrar valores acumulados hacia arriba, solo necesitamos usar \(1 - F(X)\).
Ejercicio. Un investigador informa que unos ratones a los que primero se les restringen drásticamente sus dietas y después se les enriquecen con vitaminas y proteínas vivirán un promedio de \(40\) meses. Si suponemos que la vida de tales ratones se distribuye normalmente, con una desviación estándar de \(6{,}3\) meses, calcule la probabilidad de que un ratón determinado viva a) más de \(32\) meses; b) menos de \(28\) meses; c) entre \(37\) y \(49\) meses.
Un caso particular de esta distribución, que es muy útil, es cuando \(\mu = 0\) y \(\sigma^2 = 1\), la cual da lugar a la distribución normal estándar, cuya función de densidad queda:
\[f(x) = \frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}, \quad -\infty < x < \infty,\]
la cual también se denota como \(\phi(x)\). Esto es importante porque significa que siempre es posible transformar una v.a. normal en una estándar por una simple operación:
\[Z = \frac{X - \mu}{\sigma} \sim N(0, 1)\]
que se conoce como estandarización. La importancia de este procedimiento es que el cálculo de probabilidades de una variable aleatoria normal se puede reducir al cálculo de probabilidad de una variable aleatoria de distribución normal estándar. Esto es fácil de ver ya que:
\[\begin{aligned} P(a < X < b) &= P(a - \mu < X - \mu < b - \mu) \\ &= P\left(\frac{a - \mu}{\sigma} < \frac{C - \mu}{\sigma} < \frac{b - \mu}{\sigma}\right) \\ &= P\left(\frac{a - \mu}{\sigma} < Z < \frac{b - \mu}{\sigma}\right) \end{aligned}\]Se puede demostrar que si \(X\) se distribuye como una normal estándar, entonces la variable \(-X\) también tiene distribución normal estándar, y:
\[\Phi(-x) = 1 - \Phi(x)\]
Definimos los cuantiles de la distribución normal estándar \(z_\alpha\) para cada valor de \(\alpha\) en el intervalo \((0,1)\) como aquel para el cual:
\[\Phi(z_{\alpha}) = 1 - \alpha\]
Algunos cuantiles importantes que vale la pena recordar, y que usaremos frecuentemente más adelante son: \(z_{0{,}9} = 1{,}28\), \(z_{0{,}95} = 1{,}64\), \(z_{0{,}975} = 1{,}96\) y \(z_{0{,}99} = 2{,}33\).
Ahora, mencioanmos una proposición muy útil sobre la suma de dos variables aleatorias normales.
Sean \(X_1\) y \(X_2\) dos variables aleatorias independientes con distribución \(N(\mu_1, \sigma_1^2)\) y \(N(\mu_2, \sigma_2^2)\), entonces: \[X_1 + X_2 \sim N(\mu_1 + \mu_2, \sigma_1^2 + \sigma_2^2)\]
Veamos un ejemplo.
Por ejemplo, digamos que un investigador tiene una población de ciertas bacterias en un cultivo puro que se esta estudiando por sus capacidades de producir cierta proteína transmembrana de interés, que sirve como transportador de un metabolito que se desea degradar. Se sabe que esta se produce en este cultivo con una densidad de \(35 \pm 4{,}3\) unidades por centímetro cuadrado por célula.
Sin embargo, en un accidente, el investigador mezclo dos cultivos con capacidades distintas de producir la proteína transmembrana. Este segundo cultivo tiene una capacidad menor de producir la proteína que funciona como transportador, haciendola menos efectiva en metabolizar el metabolito, con una densidad de solo \(11 \pm 7{,}1\) unidades por centímetro cuadrado por célula.
Si suponemos que la v. a. densidad de la proteína por centímetro cuadrado por célula se distribuye como una normal, entonces \(X_{\text{Cultivo 1}}\sim N(35, 18{,}49)\) y \(X_{\text{Cultivo 2}}\sim N(11, 50{,}41)\) en ambos cultivos aislados; y luego del accidente, \(X_{\text{Cultivo Mezclado}}\sim N(46, 68{,}9)\).