10.2 Distribución muestral de un estimador.
En el capítulo anterior construimos la distribución del estimador del peso promedio de una muestra de patos negros de tamaño \(n\) tomada de forma aleatoria. Dijimos que esta distribución de las medias obtenidas de cada una de esas muestras hipotéticas es conocida como distribución muestral y que esta muestra la variabilidad del estimador o los posibles valores que este puede tomar. Ahora profundizaremos en las propiedades de esta distribución que la hacen útil en inferencia estadística.
La variabilidad de la distribución muestral depende del número de observaciones que componen a la población, del número de observaciones que componen a la muestra, y del procedimiento usado para tomar la muestra de la población. Esta variabilidad se puede cuantificar en una cantidad llamada error estándar, y a medida que aumenta el tamaño de la muestra tomada, menor es el error estándar. Esto se resume en el siguiente resultado:
\[SE(\bar{X}) = \frac{\sigma}{\sqrt{n}}\]
donde \(\sigma\) es la desviación estándar poblacional. Este resultado es cierto sin importar si la distribución subyacente de la población es normal o no. El valor de la desviación estándar poblacional esta oculto a nosotros, de la misma forma que lo esta la media poblacional, y por lo tanto, también se debe estimar a partir de la muestra. Y, al igual que con la media poblacional, diferentes muestran arrojaran diferentes posibles valores del estimador, y esta variabilidad se puede resumir en la distribución muestral de la desviación estándar. Así mismo, como con otro parámetros podemos obtener estimadores de muestras, entonces estos estimadores siempre tienen asociado una distribución muestral para describir su variabilidad, y esta última se cuantifica usando la medida de error estándar.
Ejemplo. Volvamos al ejemplo de muestreo de patos negros para medir su peso total. Realizaremos simulaciones similares a la realizada antes, pero en lugar de repetir el experimento de tomar muestras miles de veces, el experimento de toma de muestra se hace una sola vez. Solo modificaremos el tamaño de la muestra obtenida de la población, de forma que no solo tomemos muestras de tamaño \(50\), sino que realizaremos la simulación usando muestras de tamaño \(20\), \(100\) y \(1000\) también. Los resultados se muestran en la figura 10.1.
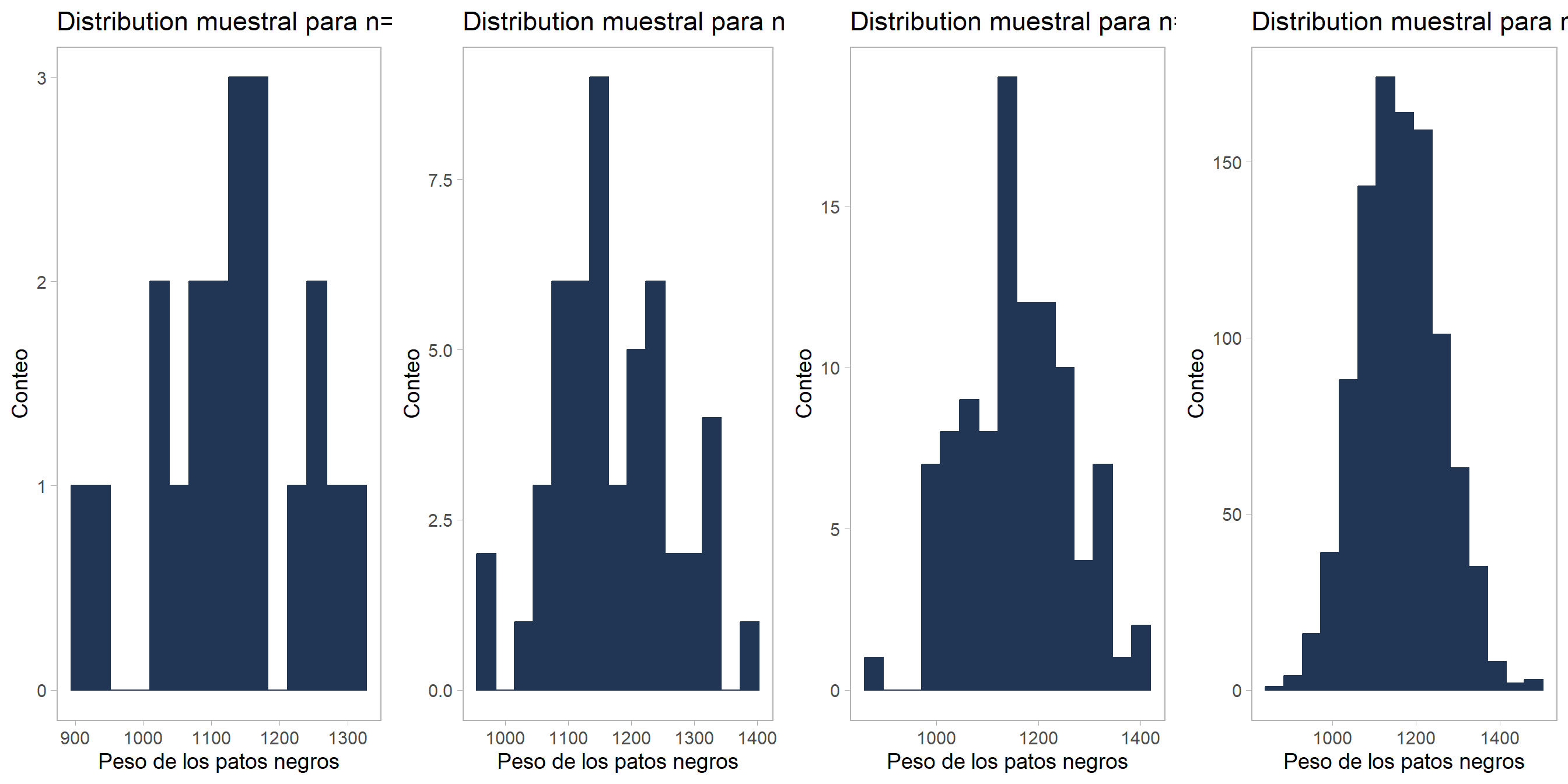
Figure 10.1: Dependencia de la distribución muestral con el tamaño de la muestra recolectada.
Vemos que en el gráfico correspondiente a la muestra más pequeña, la variabilidad es bastante grande y la mayoría de los datos se concentran alrededor de la verdadera media \(\mu = 1161\) kg. Pero se observan datos atípicos con frecuencias altas que sesgan mucho la forma de la distribución. Al aumentar el tamaño de la muestra recolectada, se puede observar que el sesgo va desapareciendo y las observaciones atípicas son cada vez menos frecuentes. De esta forma, podemos ver que el tamaño de la muestra afecta el calculo de cualquier estimador, haciendo que este este más o menos desviado del verdadero valor dependiendo del \(n\).
Ésto es fácil de cuantificar si calculamos la desviación estándar en cada simulación (que se muestra en cada uno de los gráficos de la figura anterior) y luego calculamos el error estándar, como se muestra en el siguiente fragmento de código de R:
| size | sample_size | mean | std_dev | std_error |
|---|---|---|---|---|
| small | 20 | 1125.461 | 107.63021 | 24.066846 |
| medium | 50 | 1170.217 | 92.59296 | 13.094622 |
| large | 100 | 1158.180 | 104.15617 | 10.415617 |
| very large | 1000 | 1162.193 | 96.90811 | 3.064503 |
En la tabla vemos que nuestro estimador de la media y la desviación estándar se acercan cada vez más al valor real de \(1161\) kg y \(98\) kg, y que el error estándar es cada vez más pequeño a medida que aumenta el tamaño de la muestra. Esto quiere decir que, a medida que aumentamos el tamaño de la muestra, nuestros estimadores se acercan cada vez más al valor real, y se hacen cada vez más precisos.
Este resultado se resume en uno de los teoremas más importantes de la teoría de probabilidades y estadística, la ley de los grandes números.
La ley de los grandes números. Sea \(X_1,X_2, \ldots\) una sucesión infinita de variables aleatorias independientes e idénticamente distribuidas con media finita \(\mu\). Entonces, cuando \(n \rightarrow \infty\), \[\frac{1}{n}\sum_{i=1}^{n}X_i \rightarrow \mu\] en donde la convergencia se verifica en el sentido casi seguro (ley fuerte) y también en probabilidad (ley débil).
Lo que dice el teorema es que, a medida que la muestra de la cual calculamos el estimador se hace más grande, el error en nuestra medida irá decreciendo más y más hasta converger al verdadero valor del parámetro (la convergencia casi segura y en probabilidad son formas de convergencia de una serie infinita de v. a. definidas en terminos de la probabilidad de que la convergencia se de es segura y de la probabilidad de las desviaciones tan pequelñas como se quiera del estimador y el parámetro es nula, respectivamente. Para más detalles, consulte @lehmann1999elements o @rincon2014introduccion).
Aquí un comentario pertinente sobre la notación. Si bien usamos la letra griega \(\mu\) en el teorema, misma letra que usamos para denotar la media poblacional de una distribución normal, no debemos pensar que el teorema solo es cierto oara este parámetro.
En el teorema, se usa \(\mu\) como notación más amplia de un parámetro verdadero cualquiera. Por ejemplo, si la variable aleatoría \(X\) son desviaciones estándar de la media, entonces el parámetro \(\mu\) es el resltado de promediar todas las desviaciones estándar de todas las posibles muestras reclectadas de tamaño \(n\), este promedio es \(\sigma\) y el teorema se escribiría: \[\frac{1}{n}\sum_{i=1}^{n}X_i \rightarrow \sigma\]