12.3 \(1 - \beta = P(\text{Rechazar }H_0 \vert H_1\text{ cierta})\)
12.3.1 Errores de Decisión.
Como ya hemos mencionado, desde que iniciamos el estudio de la inferencia estadística, hemos dicho que en un contexto estadístico no hay verdades absolutas. Todas nuestras conclusiones acerca de un fenómeno de estudio se hacen tomando en cuenta cierta incertidumbre inherente al experimento y que debemos cuantificar de alguna manera.
Al reportar estas conclusiones, y los resultados de nuestros análisis, debemos estar conscientes y controlar, en la medida de lo posible, dos tipos de errores en la toma de decisiones, los cuales se resumen bien en la tabla ??.
| \(H_0\text{ cierta.}\) | \(H_0\text{ falsa.}\) | |
|---|---|---|
| No rechazar \(H_0\) | Decisión Correcta | Error Tipo II |
| Rechazar \(H_0\) | Error Tipo I | Decisión Correcta |
Como podemos ver en la tabla, si el verdadero estado del experimento es que la hipótesis nula es cierta y, con la evidencia recolectada, decidimos no rechazar \(H_0\), entonces no tenemos mayor problema ya que habremos llegado a la decisión correcta. De la misma forma ocurre si el estado del experimento es que \(H_1\) es cierta y decidimos rechazar \(H_0\). El problema surge cuando tomamos decisiones equivocadas, las cuales son de dos tipos.
Decimos que cometemos error tipo I cuando decidimos rechazar la hipótesis nula siendo la hipótesis nula cierta, la cual ocurre con una probabilidad:
\[P(\text{Rechazar }H_0 \vert H_0 \text{ cierta}) = \alpha\]
En este caso, habremos recolectado una muestra muy desviada de lo esperado solo por azar. Como observamos, esta corresponde al nivel de significancia que establecemos al diseñar el experimento.
Decimos que cometemos error tipo II cuando decidimos mantener la hipótesis nula siendo la alternativa verdadera, lo cual ocurre con probabilidad:
\[P(\text{No rechazar }H_0 \vert H_1 \text{ cierta}) = \beta\]
En la figura 12.2 se representan ambos errores gráficamente.
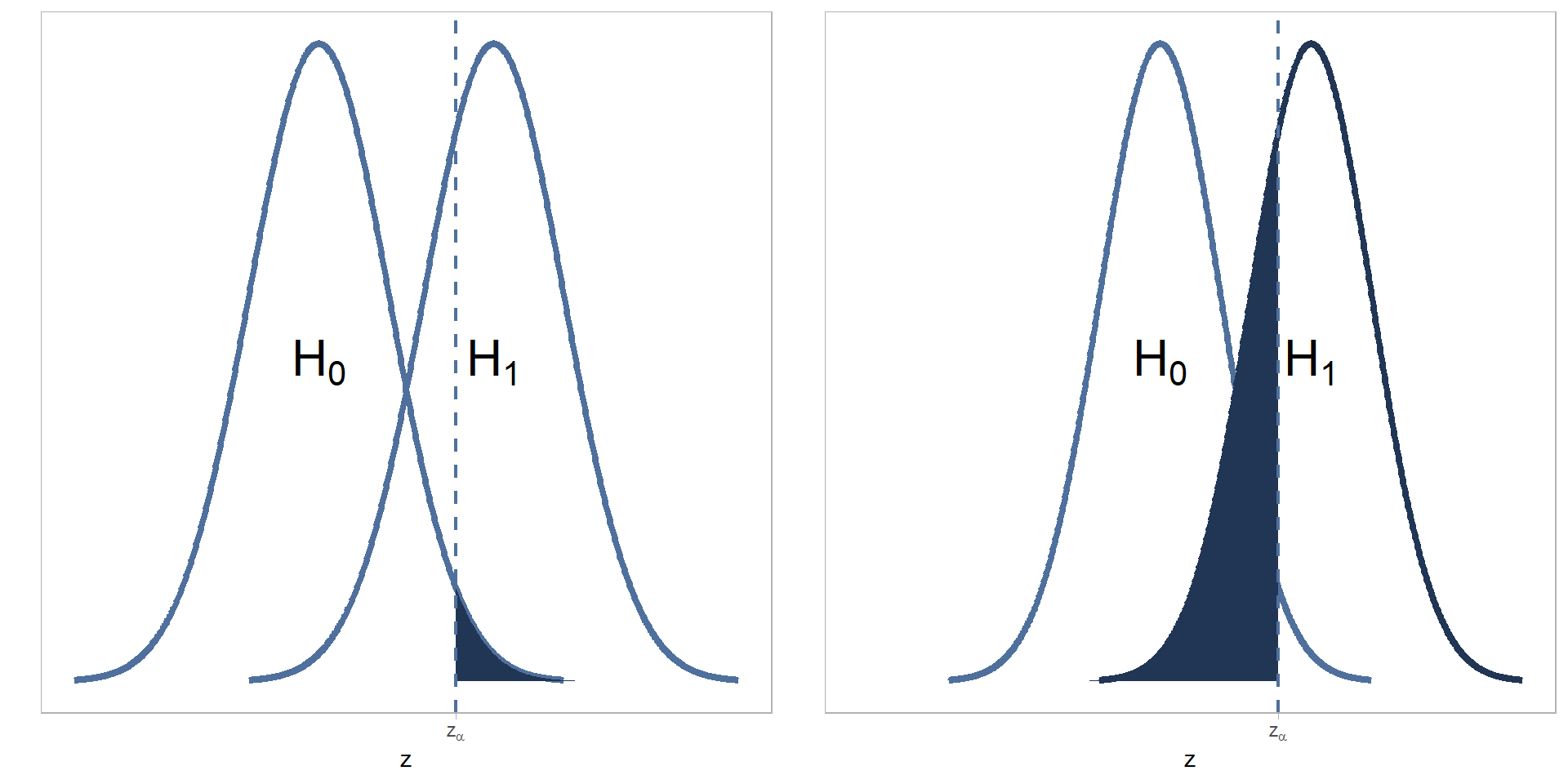
Figure 12.2: Representación gráfica de los errores de decisión asociados al contraste de hipótesis. A la izquierda el error tipo I y a la derecha el error tipo II.
Estos dos tipos de errores son inherentes a cualquier contraste de hipótesis, y los experimentos deben diseñarse de tal forma que pueda controlarse la probabilidad de cometer estos errores, dada la relevancia de las consecuencias que resultan de cometer un error de estos tipos.
Por ejemplo, antiguos estudios muestran que el germicida DDT puede acumularse en el cuerpo. En 1965 la concentración media de DDT en las partes grasas del cuerpo de las personas en Estados Unidos fue de \(9\) ppm. Se espera que, como resultado de estrictos controles, esta concentración haya decrecido. \[ \begin{aligned} H_0: & \mu \ge 9\text{ ppm} \\ H_1: & \mu < 9 \text{ ppm} \end{aligned} \]
- Si rechazamos \(H_0\) siendo esta cierta, eso quiere decir que la concentración de DDT es de 9 ppm o mayor pero decidimos que no lo es, por lo que cometemos error tipo I. Debido a esto, pensaríamos que los programas de control han sido efectivo y se tomaría la decisión de seguir gastando dinero en estos, aun cuando no son efectivos en absoluto, retardando la aplicación de nuevos controles que si pudiesen ser efectivos.
- Si fallamos en rechazar \(H_0\), siendo esta falsa, cometemos error tipo II, y concluiríamos que los controles no están siendo efectivos cuando en realidad si lo son. En este caso se desecharía un programa de control exitoso controlando las concentraciones de DDT, en el cual se ha invertido recursos importantes para su aplicación.
El ejemplo anterior pone de manifiesto las consecuencias que pueden resultar de cometer un error. Podemos ver que si cometemos error tipo I, podríamos tomar la decisión de seguir con el programa de control, pero como no es efectivo, resultaría en dinero gastado y posiblemente los casos de envenenamiento con DTT seguirían aumentando. Si cometemos error tipo II, resultaría en la eliminación de un programa que ha sido exitoso en manejar las cantidades de DDT en el ambiente. Notamos que la equivocación por error tipo I es mucho más grave dado que resulta en consecuencias directas a la salud, mientras que la eliminación del programa por error tipo II solo resultaría en la pérdida del dinero invertido.
En este caso, al diseñar el experimento, el investigador debe estar más interesado en controlar el error tipo I y mantenerlo a un valor de \(\alpha\), y no preocuparse tanto por la probabilidad cometer error tipo II. Aunque en teoría esto es cierto, la probabilidad de cometer alguno de los dos errores están relacionados, de tal forma que al disminuir la probabilidad de cometer uno, aumenta la probabilidad de cometer el otro, como se muestra en figura 12.3.
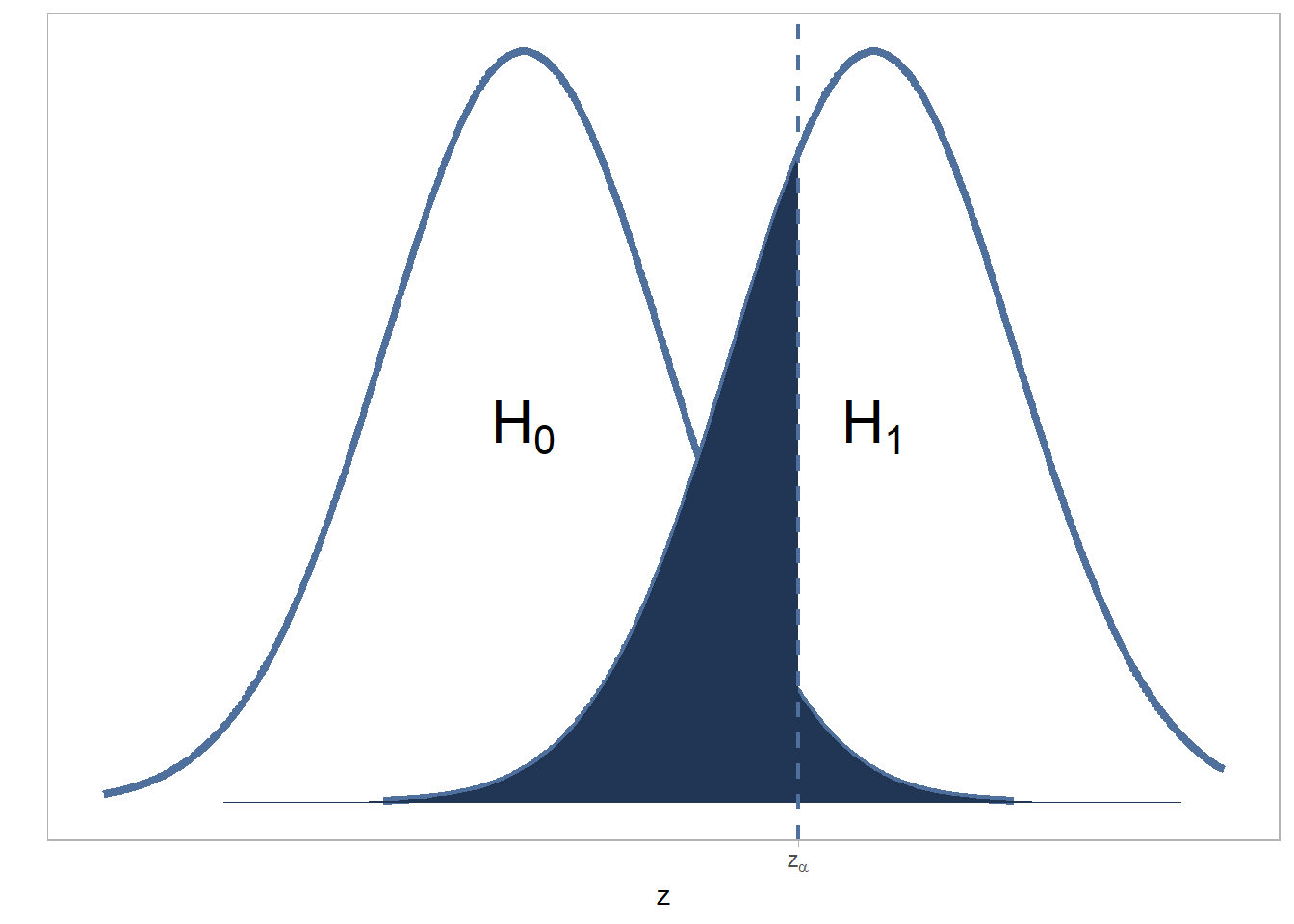
Figure 12.3: Relación entre la probabilidad de cometer error tipo I y error tipo II.
Estos errores se controlan al momento de diseñar el experimento (no se elige el valor de \(\alpha\) luego de recolectados los datos, sino mucho antes). Dado que, en general, las consecuencias de cometer error tipo I son mucho más graves que las de cometer error tipo II, lo que se suele hacer es prestablecer un valor de \(\alpha\) pequeño, y se diseña un experimento calculando el tamaño que debe tener la muestra para un valor de \(\beta\) dado, manteniendo el \(\alpha\) preestablecido. Más adelante veremos cómo realizar estos cálculos, pero primero veamos unos ejemplos.