11.3 Estimación por Intervalos.
Una estimación por intervalo de un parámetro \(\theta\) es un intervalo de la forma \(\hat{\theta}_L < \theta < \hat{\theta}_U\), donde \(\hat{\theta}_L\) y \(\hat{\theta}_U\) (los límites inferior y superior del intervalo) dependen del valor del estimador \(\hat{\Theta}\) para una muestra específica, y también de la distribución de muestreo de \(\hat{\Theta}\). Al intervalo \(\hat{\theta}_L < \theta < \hat{\theta}_U\) se le llama intervalo de confianza, y su longitud es un indicador de la precisión de una estimación puntual.
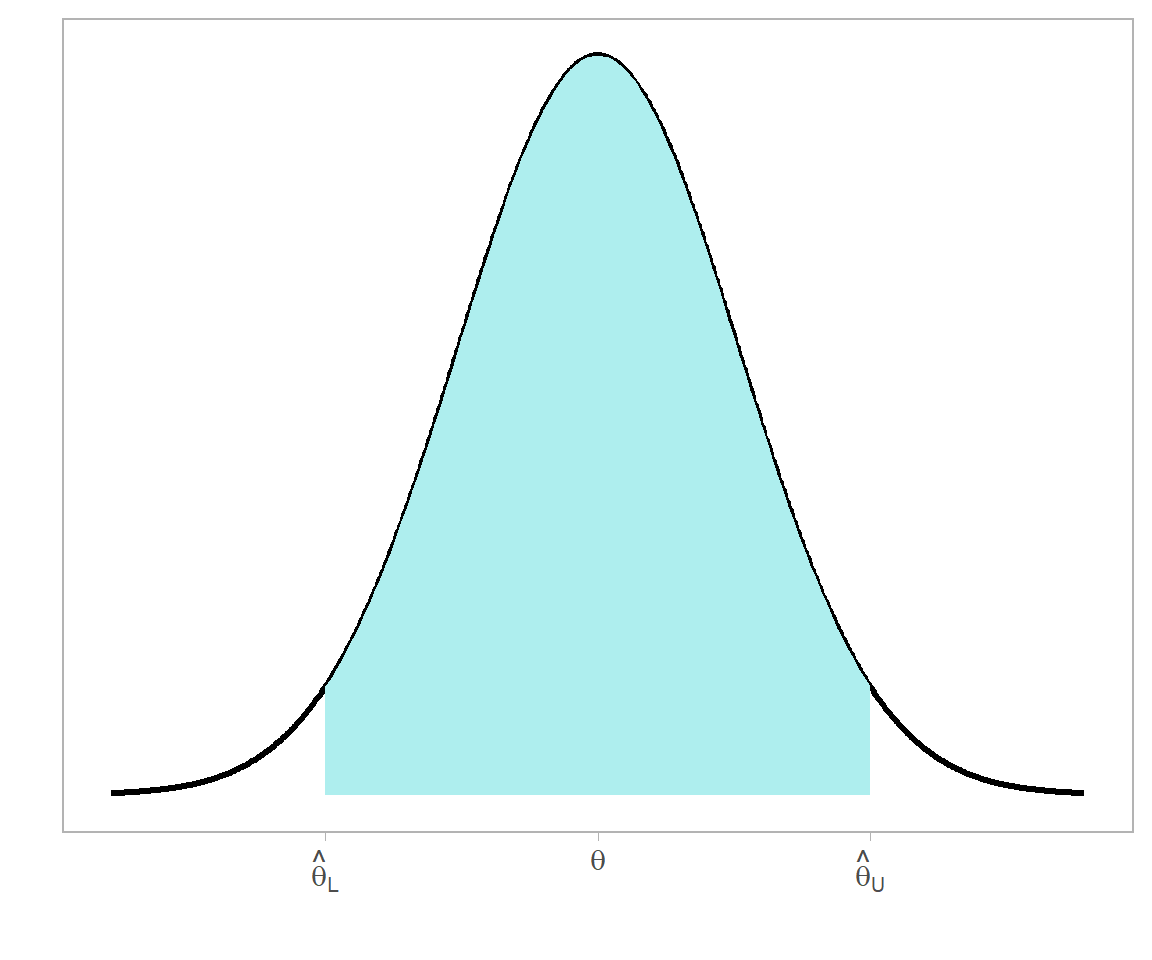
Figure 11.2: Intervalo de confianza para una variable aleatoria. El área sombreada corresponde al valor de probabilidad asociada al intervalo.
Hay que hacer énfasis en algo muy importante: los límites del intervalo son estimados a partir de la muestra, por lo que son v. a. y no se pueden entender como parámetros fijos. Esto es, son estimadores de \(\Theta_L\) \(\Theta_U\). Esto implica que cualquier medida de probabilidad asociada al intervalo se hace en términos de los límites, y no del parámetro sobre el cual se construye.
El razonamiento de la construcción de intervalos de confianza es utilizar la distribución muestral de \(\hat{\Theta}\) para determinar los límites del intervalo de tal manera que:
\[P(\hat{\Theta}_L < \theta < \hat{\Theta}_U) = 1 - \alpha, \quad 0 < \alpha < 1\]
para un valor prespecificado de \(\alpha\). Decimos que hay una probabilidad de \(1 - \alpha\) de que el intervalo contenga al verdadero valor del parámetro \(\theta\), con una confianza de \(100(1 - \alpha)\)%.
Al valor de \(\alpha\) se le conoce como nivel de significancia y es uno de los parámetros más importantes que estudiaremos, dada su importancia en la especificación del tamaño de muestras al momento de diseñar experimentos. Este valor expresa el grado de incertidumbre que esperamos a la larga sobre la veracidad del intervalo que construimos, y, por lo tanto, sobre las conclusiones que derivamos del mismo.
En general, el valor de \(\alpha\) se suele especificar como \(0{,}1\), \(0{,}05\) o \(0{,}01\) dependiendo de que tanta incertidumbre estamos dispuestos a ceder en cuanto a nuestras conclusiones y las consecuencias que derivan de presentar conclusiones equivocadas.
Por ejemplo, digamos que un médico construye un intervalo de confianza para un estudio en el que se busca probar la eficacia de cierto fármaco en curar una enfermedad. Si el investigador eligiera un nivel de significancia de \(0{,}1\), entonces el intervalo construido es del \(100(1 - 0{,}1)\% = 90\%\) de confianza, el cual puede parecer bastante grande.
Sin embargo, la incertidumbre asociada puede ser demasiado grande si notamos que el hecho de equivocarse significaría posiblemente la aparición de efectos secundarios graves sobre el paciente e incluso, la muerte de una persona. Es por ello que, dependiendo del estudio que estemos realizando, se debe escoger un nivel de confianza adecuado para asegurar que nuestras conclusiones no resulten en la toma de decisiones que puedan tener consecuencias negativas importantes.
El teorema del límite central se hace muy importante para la construcción de estadísticos cuya ley de probabilidad es conocida, tal como se estudió en la sección anterior.
11.3.1 Inferencia sobre la media.
Ahora veremos unos ejemplos de cómo usar ese formalismo para construir intervalos de confianza para distintos casos particulares. El primero de nuestros ejemplos es sobre la construcción de intervalos de confianza para una muestra para la cual se conoce la varianza poblacional.
Ejemplo. Cuando 14 estudiantes de segundo año de medicina del Bellevue Hospital midieron la presión sanguínea de la misma persona, obtuvieron los siguientes resultados: \(138, 130, 135, 140, 120, 125, 120, 130, 130, 144, 143, 140, 130\), y \(150\) mmHg. Suponiendo que se sabe que la desviación estándar poblacional es de \(10\) mmHg, construya un estimado de un intervalo de confianza del 95% de la media poblacional. De manera ideal, ¿cuál debe ser el intervalo de confianza en esta situación?
Solución. Una manera de construir un estadístico es estableciendo una expresión que nos diga cuanto se desvía nuestro estimador del valor real. Esto, ya vimos, lo podemos lograr usando una diferencia estandarizada: \[\hat{Z} = \frac{\hat{X} - \mu}{\sigma/\sqrt{n}} = \frac{133.93 - \mu}{10 / \sqrt{14}} \sim N(0, 1)\] Entonces podemos construir un intervalo de confianza del 95% (esto indica que \(0{,}95 = 1 - \alpha\), por lo que \(\alpha = 0{,}05\)) como: \[ \begin{aligned} P(z_{\alpha/2} < Z < z_{1 - \alpha/2}) &= P\left(-z_{1 - \alpha/2} < \frac{133.93 - \mu}{10 / \sqrt{14}} < z_{1 - \alpha/2}\right) = 0{,}95 \\ &= P\left(-z_{1 - \alpha/2}\frac{10}{\sqrt{14}} < 133.93 - \mu < z_{1 - \alpha/2}\frac{10}{\sqrt{14}}\right) = 0{,}95 \\ &= P\left(-133.93 - z_{1 - \alpha/2}\frac{10}{\sqrt{14}} < - \mu < -133.93 + z_{1 - \alpha/2}\frac{10}{\sqrt{14}}\right) = 0{,}95 \\ &= P\left(133.93 - z_{1 - \alpha/2}\frac{10}{\sqrt{14}} < \mu < 133.93 + z_{1 - \alpha/2}\frac{10}{\sqrt{14}}\right) = 0{,}95 \\ \end{aligned} \] Tal que el intervalo es: \[133.93 - z_{1 - \alpha/2}\frac{10}{\sqrt{14}} < \mu < 133.93 + z_{1 - \alpha/2}\frac{10}{\sqrt{14}}\] Como \(\alpha=0{,}05\), entonces \(\alpha/2=0{,}025\), y se puede saber el valor del estadístico asociado a este cuantil usando una tabla de distribución normal, o usando
qnorm(.975, 0, 1)en R. En este caso, \(z_{1 - \alpha/2} = 1.96\), de forma que: \[128.69 \text{ mmHg} < \mu < 139.17 \text{ mmHg}\] Podemos observar que el intervalo ocupa valores de presión sanguínea que podríamos considerar alta, indicando que el paciente sufre de hipertensión, de lo cual podríamos estar seguros con un 95% de confianza.
En el ejemplo anterior, usamos lo aprendido en la sección anterior sobre estadísticos sobre la media. Pero esto supone que la distribución subyacente de los datos es normal, lo cual hace obvio preguntar ¿cómo sé que mis datos son normales?
Podemos tratar de ver que tan bien se ajustan nuestros datos a nuestro supuesto de normalidad, evaluando un gráfico QQ (cuantil-cuantil). Este gráfico muestra en el eje horizontal la distribución teórica (la normal estándar) y en el eje vertical, la distribución de las observaciones. Si la distribución de las observaciones fuera normal, los puntos observados en la gráfica caerían exactamente sobre la recta central (esta corresponde a el caso teórico de esperado si la data fuera normal realmente). De otro modo, si la distribución subyacente no es normal, los puntos se desviaran más de la recta central. La forma como estos se desvían de la recta puede ayudar a indicar cuál es la distribución subyacente, o darnos cuenta de observaciones anormales o atípicas.
El siguiente es un gráfico QQ para los datos de presión sanguínea:
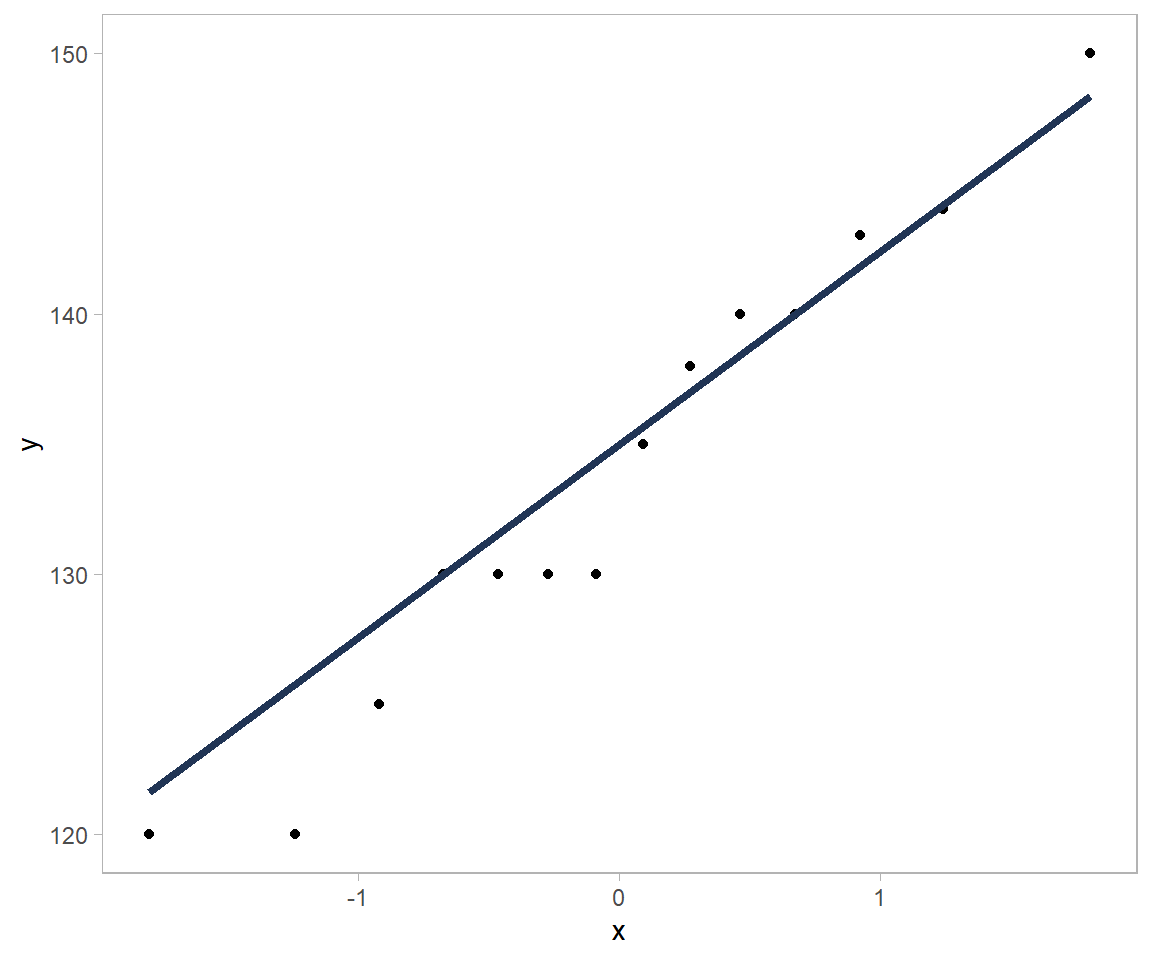
Figure 11.3: Gráfico QQ para los datos de presión sanguínea del ejemplo del texto.
Se observa en el gráfico que las observaciones que caen por debajo de la media se desvían más de la normalidad que aquellas por encima o alrededor de la media. Esto nos indica que estos valores pueden resultar ser atípicos, lo cual podría corresponder bien con la conclusión de que es bastante probable que el paciente parece tener hipertensión (lo cual hace bastante extraño obtener valores de presión menores a 128 mmHg).
Ahora, ya dijimos que el TLC es aplicable a estadísticos que son estimadores de parámetros que corresponden a distribuciones otras que la normal. Los siguientes sirven de ejemplos de inferencia sobre parámetros de una distribución Poisson y Binomial, respectivamente.
Ejemplo. Unos nutricionistas especializados en dieta canina han estado evaluando la efectividad de cierta dieta (con un componente nutricional especial) como medida para controlar la presencia de garrapatas en mascotas cuidadas bajo las mismas condiciones.
Para ello, se seleccionaron y asignaron al azar \(20\) caninos a dos grupos, 10 en cada grupo. A uno se le administró la nueva dieta, y el otro se alimentó con la misma dieta, pero sin el compuesto antiectoparásitos dado al primer grupo (este sirve como grupo control para verificar si existen diferencias). Después de un tiempo apropiado, se midió en los canino el número de garrapatas por individuo. Los datos son los siguientes:
Control: \(22, 17, 15, 7, 12, 16, 12, 14, 20, 13\)
Tratamiento: \(4, 5, 10, 7, 2, 2, 6, 10, 7, 2\)
Se desea saber si hay un cambio en el número promedio de garrapatas registrado en los caninos debido a la dieta.
Solución. La variable aleatoria se trata de un conteo por unidad de muestreo, que ya hemos estudiado corresponde bien a una ley de probabilidad Poisson. Para cada grupo, se puede calcular el valor promedio observado de garrapatas por individuos, obteniendo \(\hat{\lambda}_C = 14{,}8\) y \(\hat{\lambda}_T = 5{,}5\) (el cual recordamos corresponde también a la varianza).
Podemos obtener entonces intervalos del 95% de confianza para ambos parámetros siguiendo el procedimiento del ejemplo anterior. Construimos el estadístico: \[\hat{Z} = \frac{\hat{\lambda}_j - \lambda}{\sqrt{\hat{\lambda}_j/n}}\] donde \(j = C\) o \(j = T\), dependiendo del grupo. Y luego, aplicando TLC, sabemos que \(\hat{Z}\) sigue una distribución normal estándar. Sin embargo, el tamaño de la muestra es bastante pequeña por lo que es conveniente usar la distribución \(t\)-Student para compensar esta falta de certeza en el valor del parámetro. De forma que intervalo del 95% de confianza para el \(\lambda_C\) (el control) es: \[ \begin{aligned} 14.8 - t_{9, 1 - \alpha/2}\sqrt{\frac{14.8}{10}} < &\lambda_C < 14.8 + t_{9, 1 - \alpha/2}\sqrt{\frac{14.8}{10}} \\ 12.05 < &\lambda_C < 17.55 \end{aligned} \] y para el tratamiento: \[3.82 < \lambda_T < 7.18\] Puede observar que los intervalos para el número promedio de garrapatas por perro del control y el tratamiento no se solapan en absoluto: el control parece indicar que hay aproximadamente entre \(2\) y \(3\) veces más garrapatas en el control que en el tratamiento con la nueva dieta. Esto apoya la conclusión de que la dieta es efectiva en controlar los ectoparásitos es los caninos con un nivel de certeza del 95%.Si queremos ser más explícitos, podríamos incluso construir un intervalo de confianza para la diferencia en el número promedio de garrapatas por canino. Para ello, podemos seguir la construcción del estadístico usada anteriormente reconociendo que ahora \(\theta = \lambda_T - \lambda_C\), diferencia que denotaremos como \(D\). De esta forma: \[\hat{t} = \frac{\hat{D} - D}{SE(\hat{D})} = \frac{(\hat{\lambda}_T - \hat{\lambda}_C) - (\lambda_T - \lambda_C)}{SE(\hat{D})}\] El valor de \(SE(\hat{D})\) se calcula notando que, por los intervalos individuales, la varianza del control parece ser mayor que la del tratamiento. Entonces, podemos usar la teoría de propagación de errores como: \[SE(\hat{D}) = \sqrt{\frac{\hat{\lambda}_T}{10} + \frac{\hat{\lambda}_C}{10}} = 1.425\] Por lo tanto, escribimos el intervalo para el estadístico como: \[t_{\nu, \alpha/2} < \frac{-9.3 - (\lambda_T - \lambda_C)}{1.425} < t_{\nu, 1 - \alpha/2}\] donde el valor de \(\nu\), los grados de libertad, viene dado por la expresión: \[\nu=\frac{(\hat{\lambda}_T/n_T + \hat{\lambda}_C/n_C)^2}{[(\hat{\lambda}_T/n_T)^2/(n_T - 1) + (\hat{\lambda}_C/n_C)^2/(n_C - 1)]} = \frac{2{,}03^2}{0.277} = 14.88\] De esta forma, se tiene que el cuantil \(1 - \alpha/2\) de la distribución \(t\) con 14.88 grados de libertad es 2.13 y, luego de arreglar los términos en la expresión del intervalo, se obtiene el intervalo de confianza del 95%: \[-12.34 < \lambda_T - \lambda_C < -6.26\] Notamos que el intervalo no contiene al cero, por lo que podemos concluir con un 95% de confianza que el número promedio de garrapatas por canino es distinto en el tratamiento y el control. Además, como los límites son ambos negativos, podemos concluir también que el tratamiento con la nueva dieta resulta en un número de garrapatas por canino menor que el encontrado en el control sin la dieta.
En el ejemplo anterior debemos reconocer y enfatizar ciertas consideraciones que resultan de hacer inferencias sobre la media de dos muestras independientes. En estos casos, el estadístico se construye de la manera que dijimos al final de la sección anterior, como:
\[\frac{\hat{D} - D}{SE(D)} = \frac{(\bar{X}_1 - \bar{X}_2) - (\mu_1 - \mu_2)}{SE(\mu_1 - \mu_2)}\]
La distribución muestral depende de lo que tomamos como \(SE(\mu_1 - \mu_2)\).
- Si conocemos la varianza poblacional, entonces no necesitamos calcular \(SE(\mu_1 - \mu_2)\), y la distribución muestral es una normal estándar.
- Si no conocemos la varianza, debemos estimar \(SE(\mu_1 - \mu_2)\) a partir de los datos. En este caso, debemos tomar decisiones dependiendo de si podemos asumir que las varianzas son iguales o no.
- Si las varianzas se asumen iguales, entonces \[SE(\bar{X}_1 - \bar{X}_2) = S_{pool}\sqrt{\frac{1}{n_1} + \frac{1}{n_2}}, \quad S_{pool}^2 = \frac{(n_1 - 1)S_1^2 + (n_2 - 1)S_2^2}{n_1 + n_2 - 2}\] donde \(S_{pool}^2\) es la varianza ponderada por los grados de libertad de cada muestra particular. En este caso, la distribución muestral del estadístico es una \(t\)-Student con \(n_1 + n_2 - 2\) grados de libertad.
- Si las varianzas se asumen distintas, entonces \[SE(\bar{X}_1 - \bar{X}_2) = \sqrt{\frac{S^2_1}{n_1} + \frac{S^2_2}{n_2}}\] esto es, el error estándar es la suma de los errores estándar de las muetras por separado. En este caso, la distribución muestral del estadístico es una \(t\)-Student cuyos grados de libertad son: \[\nu=\frac{(S_1^2/n_1 + S_2^2/n_2)^2}{[(S_1^2/n_1)^2/(n_1 - 1) + (S_2^2/n_2)^2/(n_2 - 1)]}\]
Es importante que tome en cuenta estas posibilidades como hicimos en el ejemplo anterior: las varianzas no son conocidas y las asumimos distintas, por lo que usamos el caso dos del segundo inciso.
Ahora, repasamos un ejemplo que involucra un parámetro de una binomial.
Ejemplo. Se hicieron medidas del pico de dos grupos de pinzones terrestres medianos que vivían en la isla de Daphne Major, una de las islas Galápagos, durante una gran sequía en 1977. Un grupo de pinzones murió durante la sequía y otro grupo sobrevivió. Los datos de supervivientes y muertos de un total de \(36\) pinzones fueron los siguientes:
Machos: \(20\) muertos y \(27\) supervivientes.
Hembras: \(10\) muertos y \(9\) supervivientes.
Se desea saber si hay una diferencia en la proporción de pinzones supervivientes a la sequía con respecto al sexo, es decir, si la proporción de supervivientes machos es la misma que la proporción de supervivientes hembras.Solución. Si definimos la v. a. binomial superviviente como \(1\) si el pinzón sobrevivió a la sequía, y \(0\) de otro modo, entonces vemos que la variable, para machos y hembras, sigue una distribución binomial cuya probabilidad de éxito (supervivencia) \(\pi_i\) (\(i = M\) o \(H\), dependiendo de si consideramos machos o hembras, respectivamente) puede estimarse usando la proporción observada de éxitos: \[\begin{cases} p_M = \frac{27}{47} & \text{para los machos} \\ p_H = \frac{9}{19} & \text{para las hembras} \end{cases}\] Anteriormente, ya vimos que la varianza de una binomial es \(np(1-p)\), de forma que el error estándar es \(SE(p) = \sqrt{p(1-p)/ n}\). De esta forma tenemos que: \[SE(p_M) = 0.072\] y \[SE(p_H) = 0.115\] Primero, veamos como lucen intervalos de confianza del 95% para cada una de estas proporciones. Aplicando TLC, sabemos que \(p\) tiene una distribución normal, por lo que se escribe el estadístico \[\hat{t} = \frac{p_i - \pi_i}{SE(p_i)}\] para machos, \(i = M\), y hembras, \(i= H\). Note que usamos una distribución \(t\), dado que el grupo con el \(n\) más pequeño es menor que \(30\) (nuestro límite para considerar aplicable el TLC con una normal estándar). De esta forma, procedemos de la manera como ya hemos visto y obtenemos los intervalos (verifique los resultados usted mismo): \[0.429 < \pi_M < 0.72\] y \[0.233 < \pi_H < 0.714\] Notamos dos cosas en los intervalos:
- La primera es que el intervalo para las hembras es de mayor longitud que el de los machos. Esto es así, ya que el \(n\) usado para estimar los límites del intervalo es mayor en los machos que en las hembras. Esto se traduce en que tenemos una mayor certidumbre sobre el valor del parámetro para los machos que para las hembras.
- Segundo, notamos que ambos intervalos contienen el \(0{,}5\). Esto quiere decir, que la proporción observada no se puede considerar distinta de \(0{,}5\) con un 95% de confianza. Biológicamente, concluiríamos que la sequía elimino a la mitad de los individuos machos y hembras del grupo de pinzones.
- Tercero, como ambos intervalos contienen el \(0{,}5\), parece posible que estas proporciones no difieran significativamente entre sí.
El ultimo inciso, lo podemos verificar construyendo un intervalo para la diferencia en supervivencia de los pinzones machos y hembras en un solo intervalo. Primero escribimos la diferencia como \(\Delta = \pi_M - \pi_H\), la cual se estima por \(\hat{\Delta} = p_M - p_H\). De esta forma, podemos escribir el estadístico como: \[\frac{\hat{\Delta} - \Delta}{SE(\hat{\Delta})} = \frac{(p_M - p_H) - (\pi_M - \pi_H)}{SE(\hat{\Delta})}\] la cual, ya sabemos, se distribuye como una normal estándar. Se tiene que: \[SE(\hat{\Delta}) = \sqrt{\frac{p_{M} (1 - p_{M})}{n_M} + \frac{p_{H} (1 - p_{H})}{n_H}}\] Introduciendo esta expresión en el estadístico y usando la distribución muestral para el intervalo, obtenemos (verifíquelo!): \[-0.165 < \pi_M - \pi_H < 0.366\] Noten de inmediato que este intervalo contiene al cero. Es por ello que podemos concluir que, con un 95% de confianza, no hay diferencias en la proporción de hembras y machos supervivientes a la sequía.
Los ejemplos anteriores sirven para ver cómo realizar inferencia por medio de intervalos de confianza en medidas de locación para una y dos muestras independientes.
Cuando las muestras son dependientes, como cuando mides antes y después de aplicar un tratamiento experimental sobre los mismos individuos, el diseño se dice que es de medidas repetidas. En estos casos, se puede usar la diferencia entre ambos estados (antes y después) como un estadístico y tratarlo como si se tratara de una sola muestra (vea el problema 3).
Ahora, veremos cómo realizar inferencia por intervalos de confianza, pero sobre la varianza.
11.3.2 Inferencia sobre la varianza.
Como vimos antes, las inferencias sobre la varianza se pueden hacer usando como estadístico la proporción de varianzas escalada por los grados de libertad. Veamos unos ejemplos.
Ejemplo. En un estudio de los efectos sobre los bebés que tiene el consumo de cocaína durante el embarazo, se obtuvieron los siguientes datos muestrales de pesos al nacer: \(n=190\), \(\bar{x} = 2700\) g, \(S = 645\) g (según datos de Cognitive Outcomes of Preschool Children with Prenatal Cocaine Exposure, de Singer et al., Journal of American Medical Association, vol. 291, núm. 20). Utilice los datos muestrales para construir un estimado del intervalo de confianza del 95% para la desviación estándar de todos los pesos al nacer de hijos de madres que consumieron cocaína durante el embarazo. Con base en el resultado, ¿parece que la desviación estándar difiere de la desviación estándar de \(696\) g de los pesos al nacer de hijos de madres que no consumieron cocaína durante el embarazo?
Solución. Antes ya vimos que un estadístico apropiado para realizar inferencia es: \[X^2 = \frac{(n-1)S^2}{\sigma^2} \sim \chi^2(n-1)\] Como vemos, dado que conocemos la distribución muestral, podemos usarla para construir el intervalo como: \[P(\chi^2_{\alpha/2, n-1} < X^2 < \chi^2_{1-\alpha/2, n-1}) = 1 - \alpha\] Como el intervalo de confianza es del 95%, esto indica que \(0{,}95 = 1 - \alpha\), por lo que \(\alpha = 0{,}05\). Sustituyendo: \[ \begin{aligned} P(\chi^2_{\alpha/2, 189} < X^2 < \chi^2_{1 - \alpha/2, 189}) &= P\left(\chi^2_{\alpha/2, 189} < \frac{(189)(645\text{ g})^2}{\sigma^2} < \chi^2_{1 - \alpha/2, 189}\right) = 0{,}95 \\ &= P\left(\frac{1}{\chi^2_{1 - \alpha/2, 189 }} < \frac{\sigma^2}{(189)(645\text{ g})^2} < \frac{1}{\chi^2_{\alpha/2, 189}}\right) = 0{,}95 \\ &= P\left(\frac{(189)(645\text{ g})^2}{\chi^2_{1 - \alpha/2, 189}} < \sigma^2 < \frac{(189)(645\text{ g})^2}{\chi^2_{\alpha/2, 189}}\right) = 0{,}95 \end{aligned} \] Y el intervalo es: \[\frac{(189)(645\text{ g})^2}{\chi^2_{1 - \alpha/2, 189}} < \sigma^2 < \frac{(189)(645\text{ g})^2}{\chi^2_{\alpha/2, 189}}\] Como \(\alpha=0{,}05\), entonces \(\alpha/2=0{,}025\), y se puede saber el valor del estadístico asociado a este cuantil usando una tabla de distribución chi-cuadrado, o usando
qchisq(.025, 189). En este caso, \(\chi^2_{\alpha/2, 189} = 152.82\). Se procede de igual manera para el otro cuantil y se obtiene el intervalo: \[3.4341145\times 10^{5} < \sigma^2 < 5.1451145\times 10^{5}\] De forma que el intervalo para la desviación estándar se obtiene sacando raíz cuadrada: \[586.01 \text{ g} < \sigma < 717.29 \text{ g}\] Ahora, tratemos de responder la pregunta de la investigación ¿difiere la desviación estándar de los pesos de bebés de madres expuestas a cocaína de la desviación estándar de \(696\) g de bebés de madres que no se expusieron a esa droga? El intervalo de confianza construido incluye dentro de su longitud el valor de \(696\) g, por lo que no podemos decir que la desviación estándar de los pesos de los bebés de madres expuestas a cocaína difiere del valor de \(696\) g de manera significativa. Esto significa que la variabilidad de los pesos de bebés es la misma sea que provengan de madres expuestas a cocaína o no.
Ahora veamos un ejemplo aplicado a la comparación de varianzas de dos poblaciones distintas.
Se midieron los tamaños de \(30\) cráneos de gorilas hembras y \(29\) machos (datos de O’Higgins, 1989). La varianza de las hembras es \(39{,}7\), mientras que la varianza de los machos es \(105{,}9\). ¿Son las varianzas de los tamaños de cráneos de machos y hembras iguales?
Solución. Más arriba ya vimos que cuando queremos comparar dos varianzas, podemos usar el cociente entre los estadísticos construidos para estos que siguen una distribución Chi-cuadrado: \[\hat{F} = \frac{\sigma_H^2 S_M^2}{\sigma_M^2 S_H^2} \sim F(n_1 -1, n_2 - 1)\] de forma que podemos usar esta distribución muestral para construir el intervalo como: \[P(f_{\alpha/2, n_1-1, n_2-1} < F < f_{1 - \alpha/2, n_1-1, n_2-1}) = 1 - \alpha\] Si elegimos un nivel de significancia de \(0{,}05\), esto indica que \(1 - 0{,}05 = 0{,}95\), por lo que el intervalo es de 95% de confianza. Sustituyendo: \[ \begin{aligned} P(f_{\alpha/2, \nu_1, \nu_2} < F < f_{1 - \alpha/2, \nu_1, \nu_2}) &= P\left(f_{0{,}025, 29, 28} < \frac{105{,}9\sigma_H^2}{39{,}7\sigma_M^2} < f_{0{,}975, 29, 28}\right) = 0{,}95 \\ &= P\left(f_{0{,}025, 29, 28}\frac{39{,}7}{105{,}9} < \frac{\sigma_H^2}{\sigma_M^2} < f_{0{,}975, 29, 28}\frac{39{,}7}{105{,}9}\right) = 0{,}95 \\ &= P\left(\frac{1}{f_{0{,}975, 29, 28}}\frac{105{,}9}{39{,}7} < \frac{\sigma_M^2}{\sigma_H^2} < \frac{1}{f_{0{,}025, 29, 28}}\frac{105{,}9}{39{,}7}\right) = 0{,}95 \end{aligned} \] Y el intervalo es: \[\frac{1}{f_{0{,}975, 29, 28}}\frac{105{,}9}{39{,}7} < \frac{\sigma_M^2}{\sigma_H^2} < \frac{1}{f_{0{,}025, 29, 28}}\frac{105{,}9}{39{,}7}\] Para la distribución \(F\), \(f_{0{,}025, 29, 28} = 0.47\). Se procede de igual manera para el otro cuantil y se obtiene el intervalo: \[1.26 < \frac{\sigma_M^2}{\sigma_H^2} < 5.63\] ¿Qué nos dice el intervalo sobre las varianzas de los cráneos de gorilas machos y hembras? Si las varianzas fueran iguales, entonces el cociente de las varianzas sería igual a \(1\). Notamos que el \(1\) no se encuentra dentro del intervalo, por lo que podemos decir, con un \(95\)% de confianza, que la varianza de los cráneos de gorilas machos y hembras son distintas.
No solo eso, sino que además, como los límites del intervalo son mayores a \(1\), entonces la varianza de los cráneos de los gorilas machos es mayor que la varianza de los cráneos de gorilas hembras.