9.2 Frecuentistas y muestreo repetido.
Los frecuentistas, ven la probabilidad como una frecuencia a la larga, suponiendo que un experimento se repite, de forma hipotética, muchas veces. Es decir, se basa en el principio de muestreo repetido bajo las mismas condiciones. Para ellos, cualquier parámetro de importancia es fijo, y no puede tratarse como una variable aleatoria.
Se trata de entender la relación entre el estimado de una propiedad que podemos calcular y el valor real de esa propiedad, imaginándonos como podría el resultado cambiar si en lugar de la muestra seleccionada, se hubiese recolectado otra igualmente probable.
Imagine que desea conocer el peso promedio de una población de patos negros, que se distribuye como \(N(1161\text{ g}, 9604\text{ g}^2)\) (no necesariamente usted ssbe qje esta es la fistribución y, en general, no lo ssbe. Solo usamos este conocimiento para poder ralizqr simulaciones en este ejemplo), por lo que se toma una muestra aleatoria de \(n = 50\) patos. En esta muestra, encuentra que el peso promedio es \(\hat{\mu} = 1158{,}2\) g. Este peso promedio es una estimación del peso promedio verdadero de la población de \(\mu=1161\) g.
Ahora, supongamos que se realiza este experimento muchas veces, unas 10 mil veces digamos, y en cada repetición calculamos el peso promedio. En R, podemos lograr hacer esto de la siguiente forma:
# Se asume media poblacional de 1161 g y desviacion estandar poblacional de 98 g
bd_wieghts <- tibble(duck_id = 1:2300, weight = rnorm(2300, 1161, 98))
# Se realizan 10000 muestreos aleatorios de 50 observaciones de la población.
virtual_samples <- bd_wieghts %>%
rep_sample_n(size = 50, reps = 10000)
# A cada replica se le calcula el peso promedio
virtual_bd_weights <- virtual_samples %>%
group_by(replicate) %>%
summarize(`Peso Promedio` = mean(weight))
virtual_bd_weights %>%
head(10) %>%
kbl()| replicate | Peso Promedio |
|---|---|
| 1 | 1175.754 |
| 2 | 1199.270 |
| 3 | 1163.568 |
| 4 | 1161.798 |
| 5 | 1162.832 |
| 6 | 1140.051 |
| 7 | 1152.834 |
| 8 | 1178.297 |
| 9 | 1175.702 |
| 10 | 1170.830 |
Se puede observar de la tabla anterior, que algunas muestras resultan en un peso mayor al valor real de \(1161\) g, y otras en valores menores; y si inspeccionáramos cuidadosamente los resultados, podríamos verificar si de hecho el peso promedio en alguna replica es igual al valor de peso verdadero. Cada uno de esos promedios corresponde a un estimador \(\hat{\mu}\) del verdadero valor medio \(\mu\). Podríamos realizar un histograma de estos valores y veríamos que el verdadero valor esta en el centro de la distribución de valores medios obtenidos de las 10 mil replicas.
# Se realiza un grafico de los valores promedios
ggplot(virtual_bd_weights, aes(x = `Peso Promedio`)) +
geom_histogram(binwidth = 0.1, boundary = 0.4, color = "#213555") +
geom_vline(xintercept = 1161, colour = "white", linewidth = 1.2) +
labs(x = "Peso de los patos negros", y="Conteo",
title = "Distribution of 10,000 realizaciones de medidas de peso.") +
theme_light() +
theme(panel.grid = element_blank())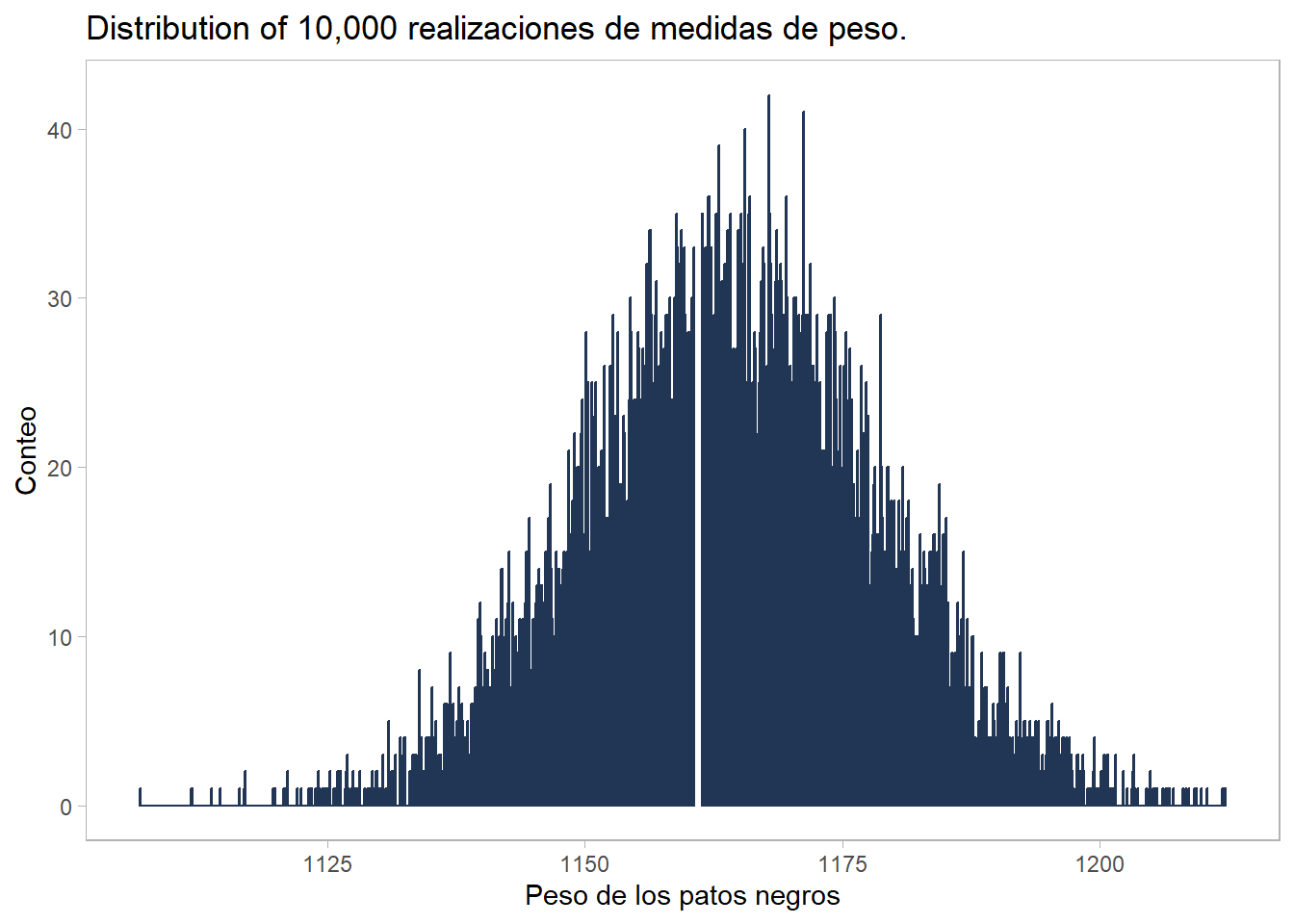
Figure 9.1: Distribución muestral de la media \(\bar{X}\) generada por simulación.
y calcular el valor promedio de los pesos promedios, que arroja un valor de 1164.27, el cual esta razonablemente en acuerdo con el valor verdadero (el valor real difiere, porque el número de replcias es finito).
El gráfico del ejemplo anterior es la distribución muestral del estadísitco \(\hat{\mu}\). Esta distribución describe la variabilidad de los promedios calculados a partir de las replicas alrededor de la media verdadera \(\mu\). Más adelante (en el capitulo Teoría de Muestreo.) estudiaremos esta distribución, pero en este punto, es importante notar que las propiedades de los estimadores que estudiaremos estan basados en el muestreo repetido hipotético (teoría frecuentista), que permite justificar el comportamiento de estos estimadores: esto es, nos permite derivar y justificar el uso de una distribución de porbabilidad para estos estimadores y, por lo tanto, justificar los resultados de inferencia estadística.