2.3 R Markdown: Estructura y Ejecución.
En esta sección no pretendo mostrarte todas las funcionalidades de R Markdown (para eso puedes consultar las referencias antes citadas que tienen más de lo que quisieras saber al respecto, y siempre puedes consultar foros y discusiones en la web para buscar ayuda), sino más bien dar una introducción breve a la tecnología de forma que puedas comenzar a realizar tus propios documentos sencillos en nada de tiempo.
2.3.1 Instalando R Markdown.
Instalar R Markdown es tan sencillo como instalar el paquete rmarkdown en R.
Para poder generar documentos de Latex vas a a necesitar instalar Latex15 (Duh!) en tu computadora. Otra forma es instalando el paquete tinytex en R y luego usar tinytex::install_tinytex()16 para instalar una versión ligera de Latex en tu computadora (la ventaja es que la instalación y uso de TinyTex no requiere de privilegios de administrador). Sea cual sea el tipo de documento que vayas a generar, necesitaras instalado Pandoc para poder generar los documentos. Puedes verificar si ya lo tienes instalado desde R usando:
Si no se encuentra instalado, puedes encontrar instrucciones de como instalarlo en https://pandoc.org/installing.html.
2.3.2 Anatomía de un documento R Markdown.
Para crear documentos de R Markdown solo tienes que especificar las tres partes esenciales que conforman el documento: el encabezado YAML, el texto con formato y los chunks de código. Un ejemplo de un documento de R Markdown muy sencillo y básico es el siguiente:
---
title: Mi primer Documento
author: Marcelo J. Molinatti S.
date: 2021-01-20
output: html_document
---
# Introducción.
Este es mi primer documento de *R Markdown* que muestra algunas de sus
funcionalidades básica. Este documento comenzó con una sección llamada
**Introducción** y continua con una subsección que muestra el uso de
*chunks* de código.
## Usando *chunks* de código.
Puedes utilizar *chunks* de código ya sea dentro de los párrafos que
escribes o usando bloques que realicen alguna función. Por ejemplo, el
siguiente bloque consiste de una simulación simple de una variable aleatoria
continua descrita por una distribución normal (que bien podría ser la
distribución de altura de una población) con media $\mu = 14$ y desviación
estándar $\sigma = 1.2$:
```{r Simulacion}
# Simula 100 datos aleatorios de una distribución normal.
sim_data <- rnorm(100, mean = 14, sd = 1.2)
# Un pequeño histograma...
hist(sim_data)
```
Luego puedes hacer uso de *chunks* en línea (*inline chunks*) usando `.
Por ejemplo, la media de los 100 datos simulados en el bloque anterior
es `r mean(sim_data)`.
Puedes guardar este ejemplo en un archivo con extensión *.rmd* (p. ej.
lo puedes llamar *mi_ejemplo.rmd*) y luego crear el documento usando la
función `render` del paquete `rmarkdown` como:
rmarkdown::render("mi_ejemplo.rmd", "html_document")Encabezado YAML
Este encabezado contiene lo que se conoce como metadata: información sobre el documento y otras instrucciones que afectan el proceso de generación del documento (también llamado rendering). Este se coloca al inicio del documento:
---
title: "Yet another course on R!"
author: "Marcelo Molinatti"
date: 2021-01-19
output: html_document
---El encabezado comienza y termina con tres guiones (—) que indican el inicio de metadatos YAML (YAML significa Yet Another Markup Language), seguido de tres campos que especifican el titulo del documento, el autor, la fecha y el formato de salida. Es importante que notes que cada campo comienza luego de introducido un espacio en blanco. Los formatos de salida pueden ser distintos: por ejemplo, html_docuemnt especifica que la salida será un archivo HTML, pdf_document especifica que la salida será un PDF, y word_document especifica que será un archivo de Word (existen otros formatos posibles. Consulta @Yihui2018).
También puedes especificar argumentos para la salida de forma que puedas modificar ciertos aspectos del documento generado. Por ejemplo:
output:
html_document:
toc: true
toc_depth: 2crea un documento HTML con secciones y subsecciones ennumeradas (toc especifica que se deben numerar y toc_depth especifica cuantos niveles numerar, en este caso, dos niveles). Date cuenta que si pasas argumentos debes indicarlo colocando dos puntos (:) y lo argumentos, si son varios, debes de colocarlos uno después del otro usando saltos de linea. También nota que cada nivel de argumento se especifica con un espacio en blanco (html_document es argumento de output y por eso tiene un espacio en blanco antes. De igual forma, ambos toc y toc_depth son argumentos de html_document y por ello se coloca otro espacio en blanco antes de estos).
Texto con formato
En esta parte va el contenido de tu documento. Tiene funcionalidades especiales que permiten agregarle formato, de forma que la presentación sea la que tu quieres. Por ejemplo, en el ejemplo, usamos encabezados que permiten definir secciones y subsecciones utilizando los numerales #. Un numeral indica un nivel o una sección del documento, y dos numerales (##) indican una subsección o segundo nivel (este es un nivel que se anida en el nivel externo. Por eso lo llamamos subsección también). Usar tres numerales implica una sub-subsección.
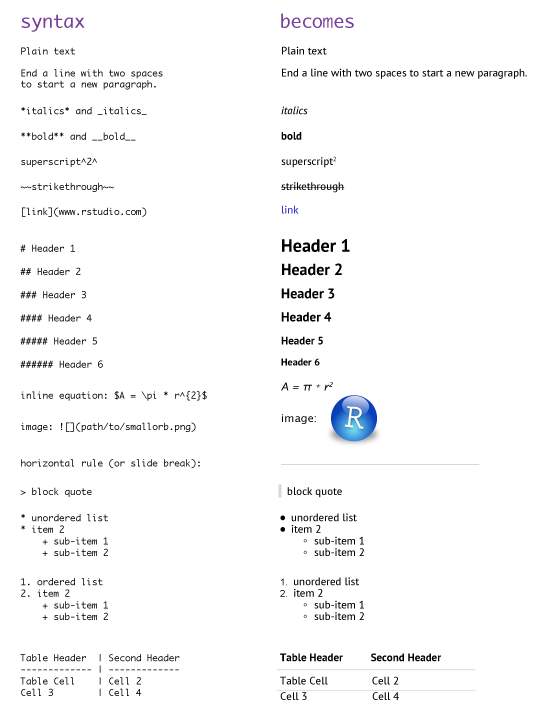
Figure 2.1: Opciones de formato de texto (izquierda) con su resultado luego de renderizado (derecha). Tomado de http://uc-r.github.io/r_markdown
Además, puedes enfatizar palabras (o îtalizar), encerrando la palabra o frase entre * (o _). Si utilizas dos * (o _) entonces la palabra o palabras son resaltadas en negritas (llamada boldface). Puedes encerrar texto que se entiende como código entre `. En el ejemplo anterior, las palabras render y rmarkdown quiero que se entiendan como código y por eso les dí ese formato.
También es posible realizar lista ordenadas (enumeradas) o no. En el caso de listas no numeradas, se pueden construir usando la notación de *. Para las listas enumeradas, se utilizan números para odenar los items. Pro ejemplo:
Esta es una lista no numerada:
* Este es el primer *item* de la lista.
* Este es el segundo *item*, el cual tine eotra lista no numerada anidada.
* Este es el primer item de la sublista, anidada en el segundo *item*.
* Este es el segundo *item* de la sublista.
* Otro *item* de la lista más externa.
Este es un ejemplo de una lista numerada u ordenada:
1. El primer *item* enumerado.
1. El segundo *item* numerado. Los número se incrementan automáticamente de forma que no
te tienes que preocupar por la numeración de cada uno de los *items*.Las listas pueden anidarse como se ve en el ejemplo anterior, simplemente utilizando una identación adecuada. Además, se pueden mezclar los tipos de lista, de forma que puedes crear listas numeradas con sublistas no numeradas, y viceversa.
Muchas otras opciones están disponibles y puedes consultarlas en @Yihui2018. En la figura 2.1 se muestran algunas opciones junto con la salida luego de renderizado el documento.
Chunks de código
La última característica de un archivo R markdown y la más importante a la hora de generar reportes es la capacidad de añadir fragmentos de código R que se ejecuta. Estos fragmentos pueden resultar en salidas (o outputs, como imágenes, tablas, datos, etc.) que se imprimen y se muestran en el documento generado por la función render al compilar el documento.
Para colocar un fragmento de código, colocas {r } encerrado entre tres ` como se muestra en el fragmento que usamos de ejemplo. Luego, colocas el código de R seguido de la última llave (lo cual puede ser el cargado de los datos y paquetes, la manipulación de los datos, análisis estadísticos, entre otras muchas cosas más). Puedes colocar más de un fragmento de código en un documento y cada fragmento nombrarlo usando una etiqueta: para ello, solo coloca un nombre apropiado seguido de la r, dentro de las llaves (p. ej. {r Simulacion} denota un fragmento de código llamado Simulacion. Date cuenta que, como hemos aprendido hasta ahora, la etiqueta debe ser una descripción significativa del fragmento de código). También, los fragmentos de código reciben argumentos: luego de la etiqueta o nombre, se coloca una coma seguido de los argumentos. Algunos argumentos importantes son:
echoes un valor lógico que si esTRUE, permite que se imprima el fragmento de código. De lo contrario, el fragmento de código es evaluado (y cualquier resultado aparecera en el reporte final) pero el código no se mostrará en el documento.evales un valor lógico que si esTRUE, el fragmento de código se ejecuta, de lo contrario, el fragmento de código no se ejecuta (y por lo tanto no hay resultados generados por ese fragmento).includees un valor lógico que de serFALSE, permite que el código se ejecute, sin incluir el código y los resultados en el documento final.messageywarningson también valores lógicos que permiten decidir si se quiere que aparezcan mensajes y advertencias en el documento final.results = 'hide'yfig.show = 'hide'es una forma conveniente de hacer que que no se muestren las salidas y gráficos, respectivamente.
Otra funcionalidad de los fragmentos de código es que puedes usar inline chunks (o fragmentos en línea) dentro del texto o contenido. Para ello solo usas r encerrada entre ` (como en `r mean(sim_data)` en el ejemplo). Estos fragmentos sirven para colocar información almacenada en objetos de R, en el contenido del documento (no es tan adecuado para escribir grandes fragmentos de código. En esos casos, es mejor usar un chunk completo).
2.3.3 Imágenes y tablas.
Otra parte importante es la capacidad de añadir imágenes y tablas a documentos generados por R Markdown. Para añadir imágenes puedes utilizar el comando:
Una mejor manera de añadir imágenes a un documento es por medio de la función knitr::include_graphics17 incluida en el paquete knitr.
```{r my-figure, echo = FALSE, out.width='70%', fig.align='center'}
knitr::include_graphics("ruta/a/img.png")
```La utilidad de esta forma de incluir imágenes es que facilita la personalización por medio de las opciones en los chunks de código. Se pueden utilizar opciones como width, height, fig.align, fig.cap, y/o out.width para especificar el tamaño de la imagen, la alineación, la leyenda de la figura o el tamaño relativo a la amplitud del texto. El poder incluir imágenes a partir de fragmentos de código es lo que permite añadir gráficos generados en R a un documento. En el ejemplo que usamos de base, luego de renderizado el documento vas a a ver un histograma de los datos simulados. Este histograma es generado con la función hist en R, y por lo tanto se imprime en el documento final y, al igual que antes, se puede personalizar su presentación con las opciones del chunk de código.
En cuanto a las tablas, la forma más sencilla de generar tablas de datos con un formato personalizado que sea visualmente agradable es utilizando funcione de formato de tablas como knitr::kable(). Por ejemplo, ya dijimos que un conjunto de datos que sirve mucho para aprender a realizar análisis estadísticos en R es mtcars. Un ejemplo de uso de la función de formato de tablas es:
```{r my-table}
knitr::kable(
mtcars[1:5, ],
caption = "A knitr kable."
)
```Date un tiempo para leer los argumentos de la función kable de forma que puedas personalizar aun más las tablas que se generan en tus documentos (¿Recuerdas como se lee la documentación de una función?). Otro paquete importante que permite añadir otras características a las tablas es el paquete kableExtra el cual permite estilizar y crear tablas más complejas si así se requiere. Otros paquetes que permiten imprimir tablas más personalizadas son paquetes como xtable, stargazer, pander, tables, y ascii.
2.3.4 Bibliografía y referencias.
Es posible generar de forma automática citas y bibliografías en el documento final. Lo único que se tiene que hacer es especificar un archivo de bibliografía usando el campo bibliography en el encabezado YAML. El campo debe especificar la dirección o ruta de acceso del archivo que contiene la bibliografía, y la bibliografía puede estar en formato BibLaTeX, BibTeX, endnote y mnedline. Una forma de automatizar el proceso de creación de una bibliografía es utilizando un manejador de biblioteca (como por ejemplo Mendeley Desktop) de forma que cree el archivo bibliográfico y tu solo tienes que hacer referencia a la dirección de la misma para incluirla en el documento.
Para citar algún autor en tu archivo .Rmd se utiliza una clave compuesta por el símbolo @ seguido de un identificador de alguna referencia en el archivo bibliográfico (por ejemplo, @marcelo2020). Si colocas la cita encerrada entre corchetes, entonces la cita es colocada entre paréntesis. Si quieres colocar más de una cita, cada una debe ir separada de la otra por un ; (como en [@marcelo2020; @rodriguez2010]). También puedes añadir comentarios arbitrarios (como cuando se busca hacer referencia a una pagina específica dentro de un trabajo, como en [véase @marcelo2020, pp. 33-35]). Si quieres colocar una cita en el texto (como en … Según Molinatti (2020), …) entonces se omiten los corchetes, y si quieres que solo se imprima la fecha de la publicación a la que haces referencia, pero no el autor, se coloca un - antes del inicio de la cita (como en [-@marcelo2020]).
Al renderizar el documento, se construye la bibliografía y se añade al final del documento de forma automática, la cual contendrá cada una de las citas referenciadas dentro del documento. Sin embargo, no se genera una encabezado de forma automática, por lo que es costumbre añadir en un documento un último encabezado o sección para la bibliografía:
# Bibliografía.También puedes cambiar el estilo de las referencias (p. ej., si quieres usar las normas APA, puedes usar un documento de estilo que genere las referencias siguiendo estas normas) al hacer uso de un archivo CSL (citation style language) en el campo csldel encabezado YAML.
bibliography: bibliografia.bib
csl: apa.cslEl campo csl debe contener la dirección al archivo con extensión .csl (puedes encontrar estilos bibliográficos en http://github.com/citation-style-language/styles). en el ejemplo anterior, se asume que ambos, bibliografía y estilo (bibliografia.bib y apa.csl, respectivamente) están en el mismo directorio que tu archivo .Rmd.
Una vez que se tiene un archivo .Rmd puedes proceder a realizar el renderizado para obtener tu documento. Lo se hace es que una vez finalizado, utilizas la función rmarkdown::render (en el archivo que nos sirve de ejemplo, se utiliza en la consola como rmarkdown::render("mi_ejemplo.rmd", "html_document"), de forma que se obtiene el resultado en forma de un archivo HTML), la cual se encarga de pasar el archivo a knitr, el cual se encarga de ejecutar todos los fragmentos de código (estos se ejecutan primero antes del compilado del documento, lo cual se puede aprovechar para colocar fragmentos de código incluso en el encabezado YAML) y crea un documento markdown (extensión .md). Luego Pandoc se encarga de procesar este archivo para generar el documento deseado, ya sea en HTML, PDF, o un documento de Word, presentaciones, entre otros.

Listo. Ya puedes comenzar a llevar a cabo reportes, informes, presentaciones y otros documentos que te interesen. En la bibliografía puedes encontrar mucha más información, de forma que seas capaz de explotar todas las funcionalidades que ofrece RMarkdown.
Puedes encontrar una en miktex.org. En el caso de Linux, puedes instalarlo desde el repositorio o usar la misma versión de MikTex.↩︎
De aquí en adelante la notación de los pares de dos puntos aparecerá seguido. El operador
::es conocido como operador de resolución de ámbito. Cuando se utiliza como<paquete>::<funcion>(), lo que se hace es especificar que la función llamada<funcion>pertenece al paquete llamado<paquete>. Por ejemplo,tinytex::install_tinytex()indica que la funcióninstall_tinytexes una función incluida en el paquetetinytex. Sirve para evitar conflictos o ambigüedades a la hora de llamar funciones. Si hay dos funciones llamadas de la misma forma pero en paquetes diferentes, puedes usar el operador::y el nombre del paquete para especificar cual de las dos funciones es la que vas a usar.↩︎Recuerda que
::es el operador de resolución de ámbito. Por lo tanto,include_graphicses una función incluida en el paqueteknitr, y por lo tanto, este debe estar instalado.↩︎